Predicción más próxima. CNN
Python
Publicado el 21 de Enero del 2024 por Hilario (122 códigos)
158 visualizaciones desde el 21 de Enero del 2024
La última imagen corresponde a la EPOCH número 3.
-----------------------------------------------------------------------
**********************************************************************************************************************
MANUAL PREDICCIÓN PRÓXIMA A DECISIÓN.
------------------------------------
Ejercicio_IA_Aula_08.py
-----------------------
Este código implementa una red convolucional (CNN) utilizando el conjunto de datos CIFAR-10 para clasificación de imágenes. Aquí hay una explicación sencilla de lo que hace el ejercicio:
Carga y Preprocesamiento de Datos:
-----------------------------------------------
Importa las bibliotecas necesarias y carga el conjunto de datos CIFAR-10.
Normaliza las imágenes dividiendo los valores de píxeles por 255.
Convierte las etiquetas de clase a formato categórico.
Creación de Generadores de Datos:
Define generadores de datos para el entrenamiento y la validación, aplicando aumentación de datos en el conjunto de entrenamiento.
Definición del Modelo CNN:
-------------------------
Crea un modelo secuencial de CNN con capas convolucionales, activaciones ReLU, capas de max-pooling, una capa Flatten, capas Dense y una capa de salida con activación softmax.
Utiliza la función de pérdida 'categorical_crossentropy', el optimizador 'rmsprop' y mide la precisión durante el entrenamiento.
Entrenamiento del Modelo:
-----------------------
Entrena el modelo en varios epochs utilizando el generador de entrenamiento y el generador de validación.
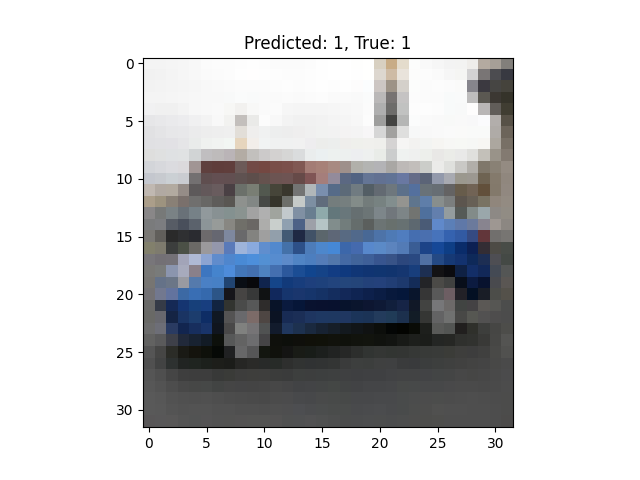
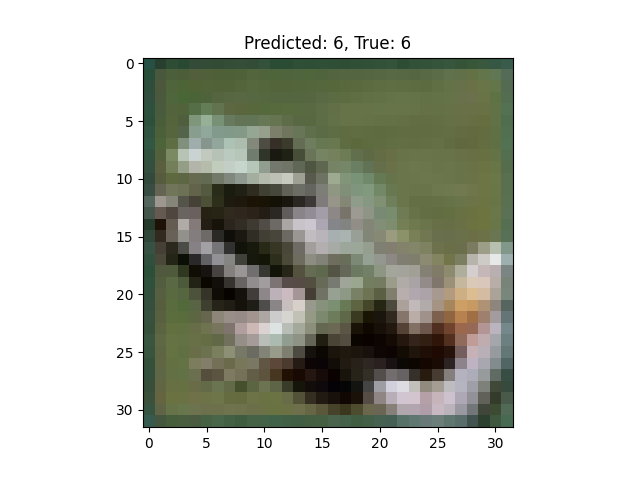
Después de cada epoch, muestra algunas imágenes del conjunto de validación junto con las predicciones del modelo.
Mostrar Resultados Finales:
--------------------------
Muestra los resultados finales, incluyendo la precisión alcanzada en la última epoch.
Visualización de Imágenes en Decisiones:
Define una función (show_images_on_decision) para visualizar imágenes del conjunto de validación junto con las predicciones del modelo.
En resumen, este código implementa y entrena una CNN para clasificación de imágenes en el conjunto de datos CIFAR-10, y muestra algunas imágenes junto con las predicciones del modelo después de cada epoch de entrenamiento.
LAS BIBLIOTECAS QUE UTILIZAREMOS SERÁN LOS SIGUIENTES:
------------------------------------------------------
numpy: Módulo de la librería de matemáticas NumPy para trabajar con matrices y vectores
matplotlib: Módulo de la librería de visualización Matplotlib para crear gráficos y visualizaciones
keras.datasets: Módulo de la biblioteca Keras para cargar y trabajar con conjuntos de datos predefinidos
keras.utils: Módulo de la biblioteca Keras para convertir etiquetas de variables categóricas en matrices numéricas
keras.preprocessing.image: Módulo de la biblioteca Keras para preprocesar imágenes
keras.models: Módulo de la biblioteca Keras para crear y administrar modelos de redes neuronales
keras.layers: Módulo de la biblioteca Keras para definir y agregar capas a los modelos de redes neuronales
keras.backend: Módulo de la biblioteca Keras para acceder a las funciones y variables del backend de TensorFlow
****************************************************************************************************************
Establecimiento de parámetros:
-----------------------------
Se establecen algunos parámetros relevantes para el modelo de red neuronal:
modo: Modo de clasificación utilizado, "categorical" para multiclase o "binary" para binaria
dimension: Dimensión de las imágenes de entrenamiento (32x32 en este caso)
Carga del conjunto de datos CIFAR-10
Se carga el conjunto de datos CIFAR-10, que contiene imágenes de 60,000 objetos de 10 clases diferentes. Las imágenes se dividen en conjuntos de entrenamiento y validación.
Preprocesamiento de imágenes:
----------------------------
Las imágenes se convierten en formato float y se escalan entre 0 y 1. Además, se representan en formato categórico para la clasificación multiclase.
Generación de datos con transformación:
Se utilizan dos generadores de datos para preprocesar las imágenes durante el entrenamiento y la validación. Estos generadores aplican transformaciones como escalado, giro y volteo para aumentar la diversidad del dataset y mejorar el rendimiento del modelo.
Creación del modelo de red neuronal:
----------------------------------
Se crea un modelo de red neuronal convolucional secuencial utilizando el módulo Sequential de Keras. El modelo consta de las siguientes capas:
Capas convolucionales:
---------------------
Tres capas convolucionales con filtros de 16, 32 y 64 filtros, respectivamente. Estas capas extraen características espaciales de las imágenes.
Funciones de activación:
-----------------------
Se utiliza la función de activación ReLU después de cada capa convolucional para mejorar la selectividad de las características extraídas.
"Polinización" máxima:
-------------------
Se utiliza la capa de maxpooling después de cada capa convolucional para reducir la dimensionalidad de las representaciones espaciales sin perder información importante.
Flatten:
-------
Se utiliza una capa de aplanamiento para convertir las matrices bidimensionales de características en vectores unidimensionales.
Capas densas:
-----------
Se agregan dos capas densas con 64 y 10 neuronas, respectivamente. Estas capas representan la parte final del modelo, donde se realiza la clasificación.
Función de activación final: La última capa utiliza la función de activación softmax para generar probabilidades de pertenencia a cada una de las 10 clases.
Compilación del modelo.
**********************
Se compila el modelo definiendo las funciones de pérdida y optimizador. La función de pérdida utilizada es la entropía cruzada categórica para la clasificación multiclase, y el optimizador utilizado es el RMSprop, un algoritmo de optimización eficiente para redes neuronales convolucionales.
Entrenamiento del modelo.
***********************
Se entrena el modelo durante 5 épocas, utilizando los conjuntos de entrenamiento y validación. En cada época, el modelo se ajusta a los datos de entrenamiento y se evalúa en los datos de validación para monitorear su progreso.
Función para mostrar imágenes de decisión
****************************************
Se define una función show_images_on_decision que muestra imágenes del conjunto de validación y sus predicciones. Esta función se utiliza después de cada época para visualizar cómo está funcionando el modelo.
Resultados finales
*****************
Al final del entrenamiento, se imprimen los resultados finales, incluyendo la precisión del modelo en el conjunto de validación.
------------------------------------------------------------------------------------------------------------
El ejercicio fue realizado en una plataforma Linux.
Ubuntu 20.04.6 LTS.
Editado en Sublime text.
Ejecución bajo consola de linux:
--------------------------------------------------------------------------------------------
También se puede editar y ejecutar con GOOGLE COLAB.
********************************************************************************************************************
SALIDA DEL EJERCICIO DESPUES DE 5 CICLOS O EPOCH, CON LA PRECISIÓN OBTENIDA.
***************************************************************************
Epoch 1/5
3125/3125 [==============================] - 55s 17ms/step - loss: 1.7981 - accuracy: 0.3388 - val_loss: 1.4368 - val_accuracy: 0.4725
1/1 [==============================] - 0s 122ms/step
Epoch 2/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.5218 - accuracy: 0.4575 - val_loss: 1.3205 - val_accuracy: 0.5330
1/1 [==============================] - 0s 24ms/step
Epoch 3/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4376 - accuracy: 0.5005 - val_loss: 1.2920 - val_accuracy: 0.5522
1/1 [==============================] - 0s 24ms/step
Epoch 4/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4429 - accuracy: 0.5088 - val_loss: 1.4771 - val_accuracy: 0.4987
1/1 [==============================] - 0s 24ms/step
Epoch 5/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4649 - accuracy: 0.5012 - val_loss: 1.3029 - val_accuracy: 0.5609
1/1 [==============================] - 0s 24ms/step
_____________________________________________________
| Dimension | Capa | Filtro | Precision |
_____________________________________________________
| 32 | 3 | [64] | 50.1240015 |
_____________________________________________________
-----------------------------------------------------------------------
**********************************************************************************************************************
MANUAL PREDICCIÓN PRÓXIMA A DECISIÓN.
------------------------------------
Ejercicio_IA_Aula_08.py
-----------------------
Este código implementa una red convolucional (CNN) utilizando el conjunto de datos CIFAR-10 para clasificación de imágenes. Aquí hay una explicación sencilla de lo que hace el ejercicio:
Carga y Preprocesamiento de Datos:
-----------------------------------------------
Importa las bibliotecas necesarias y carga el conjunto de datos CIFAR-10.
Normaliza las imágenes dividiendo los valores de píxeles por 255.
Convierte las etiquetas de clase a formato categórico.
Creación de Generadores de Datos:
Define generadores de datos para el entrenamiento y la validación, aplicando aumentación de datos en el conjunto de entrenamiento.
Definición del Modelo CNN:
-------------------------
Crea un modelo secuencial de CNN con capas convolucionales, activaciones ReLU, capas de max-pooling, una capa Flatten, capas Dense y una capa de salida con activación softmax.
Utiliza la función de pérdida 'categorical_crossentropy', el optimizador 'rmsprop' y mide la precisión durante el entrenamiento.
Entrenamiento del Modelo:
-----------------------
Entrena el modelo en varios epochs utilizando el generador de entrenamiento y el generador de validación.
Después de cada epoch, muestra algunas imágenes del conjunto de validación junto con las predicciones del modelo.
Mostrar Resultados Finales:
--------------------------
Muestra los resultados finales, incluyendo la precisión alcanzada en la última epoch.
Visualización de Imágenes en Decisiones:
Define una función (show_images_on_decision) para visualizar imágenes del conjunto de validación junto con las predicciones del modelo.
En resumen, este código implementa y entrena una CNN para clasificación de imágenes en el conjunto de datos CIFAR-10, y muestra algunas imágenes junto con las predicciones del modelo después de cada epoch de entrenamiento.
LAS BIBLIOTECAS QUE UTILIZAREMOS SERÁN LOS SIGUIENTES:
------------------------------------------------------
numpy: Módulo de la librería de matemáticas NumPy para trabajar con matrices y vectores
matplotlib: Módulo de la librería de visualización Matplotlib para crear gráficos y visualizaciones
keras.datasets: Módulo de la biblioteca Keras para cargar y trabajar con conjuntos de datos predefinidos
keras.utils: Módulo de la biblioteca Keras para convertir etiquetas de variables categóricas en matrices numéricas
keras.preprocessing.image: Módulo de la biblioteca Keras para preprocesar imágenes
keras.models: Módulo de la biblioteca Keras para crear y administrar modelos de redes neuronales
keras.layers: Módulo de la biblioteca Keras para definir y agregar capas a los modelos de redes neuronales
keras.backend: Módulo de la biblioteca Keras para acceder a las funciones y variables del backend de TensorFlow
****************************************************************************************************************
Establecimiento de parámetros:
-----------------------------
Se establecen algunos parámetros relevantes para el modelo de red neuronal:
modo: Modo de clasificación utilizado, "categorical" para multiclase o "binary" para binaria
dimension: Dimensión de las imágenes de entrenamiento (32x32 en este caso)
Carga del conjunto de datos CIFAR-10
Se carga el conjunto de datos CIFAR-10, que contiene imágenes de 60,000 objetos de 10 clases diferentes. Las imágenes se dividen en conjuntos de entrenamiento y validación.
Preprocesamiento de imágenes:
----------------------------
Las imágenes se convierten en formato float y se escalan entre 0 y 1. Además, se representan en formato categórico para la clasificación multiclase.
Generación de datos con transformación:
Se utilizan dos generadores de datos para preprocesar las imágenes durante el entrenamiento y la validación. Estos generadores aplican transformaciones como escalado, giro y volteo para aumentar la diversidad del dataset y mejorar el rendimiento del modelo.
Creación del modelo de red neuronal:
----------------------------------
Se crea un modelo de red neuronal convolucional secuencial utilizando el módulo Sequential de Keras. El modelo consta de las siguientes capas:
Capas convolucionales:
---------------------
Tres capas convolucionales con filtros de 16, 32 y 64 filtros, respectivamente. Estas capas extraen características espaciales de las imágenes.
Funciones de activación:
-----------------------
Se utiliza la función de activación ReLU después de cada capa convolucional para mejorar la selectividad de las características extraídas.
"Polinización" máxima:
-------------------
Se utiliza la capa de maxpooling después de cada capa convolucional para reducir la dimensionalidad de las representaciones espaciales sin perder información importante.
Flatten:
-------
Se utiliza una capa de aplanamiento para convertir las matrices bidimensionales de características en vectores unidimensionales.
Capas densas:
-----------
Se agregan dos capas densas con 64 y 10 neuronas, respectivamente. Estas capas representan la parte final del modelo, donde se realiza la clasificación.
Función de activación final: La última capa utiliza la función de activación softmax para generar probabilidades de pertenencia a cada una de las 10 clases.
Compilación del modelo.
**********************
Se compila el modelo definiendo las funciones de pérdida y optimizador. La función de pérdida utilizada es la entropía cruzada categórica para la clasificación multiclase, y el optimizador utilizado es el RMSprop, un algoritmo de optimización eficiente para redes neuronales convolucionales.
Entrenamiento del modelo.
***********************
Se entrena el modelo durante 5 épocas, utilizando los conjuntos de entrenamiento y validación. En cada época, el modelo se ajusta a los datos de entrenamiento y se evalúa en los datos de validación para monitorear su progreso.
Función para mostrar imágenes de decisión
****************************************
Se define una función show_images_on_decision que muestra imágenes del conjunto de validación y sus predicciones. Esta función se utiliza después de cada época para visualizar cómo está funcionando el modelo.
Resultados finales
*****************
Al final del entrenamiento, se imprimen los resultados finales, incluyendo la precisión del modelo en el conjunto de validación.
------------------------------------------------------------------------------------------------------------
El ejercicio fue realizado en una plataforma Linux.
Ubuntu 20.04.6 LTS.
Editado en Sublime text.
Ejecución bajo consola de linux:
--------------------------------------------------------------------------------------------
También se puede editar y ejecutar con GOOGLE COLAB.
********************************************************************************************************************
SALIDA DEL EJERCICIO DESPUES DE 5 CICLOS O EPOCH, CON LA PRECISIÓN OBTENIDA.
***************************************************************************
Epoch 1/5
3125/3125 [==============================] - 55s 17ms/step - loss: 1.7981 - accuracy: 0.3388 - val_loss: 1.4368 - val_accuracy: 0.4725
1/1 [==============================] - 0s 122ms/step
Epoch 2/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.5218 - accuracy: 0.4575 - val_loss: 1.3205 - val_accuracy: 0.5330
1/1 [==============================] - 0s 24ms/step
Epoch 3/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4376 - accuracy: 0.5005 - val_loss: 1.2920 - val_accuracy: 0.5522
1/1 [==============================] - 0s 24ms/step
Epoch 4/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4429 - accuracy: 0.5088 - val_loss: 1.4771 - val_accuracy: 0.4987
1/1 [==============================] - 0s 24ms/step
Epoch 5/5
3125/3125 [==============================] - 54s 17ms/step - loss: 1.4649 - accuracy: 0.5012 - val_loss: 1.3029 - val_accuracy: 0.5609
1/1 [==============================] - 0s 24ms/step
_____________________________________________________
| Dimension | Capa | Filtro | Precision |
_____________________________________________________
| 32 | 3 | [64] | 50.1240015 |
_____________________________________________________