Clasificacion de Datos Arboles de Decision
Python
Publicado el 17 de Octubre del 2023 por Hilario (129 códigos)
448 visualizaciones desde el 17 de Octubre del 2023
-----------------------------------------------------------------------------
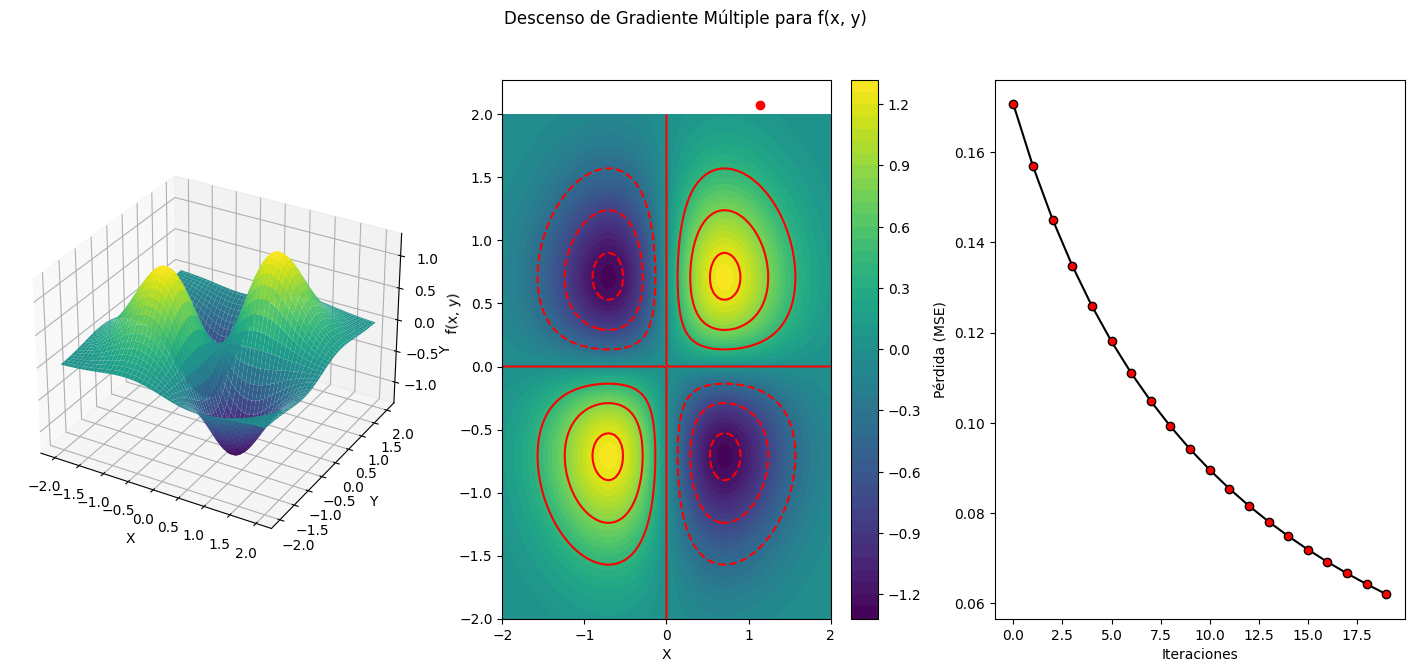
La clasificación de datos mediante árboles de decisiones es un método de aprendizaje automático que se utiliza para categorizar o etiquetar datos en diferentes clases o categorías. Es una técnica de modelado predictivo que se basa en la creación de un "árbol" de decisiones, donde cada nodo interno del árbol representa una pregunta o una prueba sobre una característica específica de los datos, y las ramas que salen de ese nodo conducen a diferentes resultados o decisiones basadas en el valor de esa característica. Los nodos hoja del árbol representan las categorías o clases en las que se divide el conjunto de datos.
El proceso de clasificación a través de árboles de decisión implica:
Construcción del árbol: Se inicia con un nodo raíz que representa todo el conjunto de datos. Luego, se selecciona una característica y un umbral que se utilizará para dividir los datos en dos subconjuntos. Este proceso se repite recursivamente en cada subconjunto hasta que se alcanza un criterio de parada, como un tamaño máximo de profundidad del árbol, una cantidad mínima de muestras en los nodos hoja, o una impureza mínima.
Selección de características: En cada paso de división, se elige la característica que mejor separa los datos, lo que se logra al minimizar alguna métrica de impureza, como el índice de Gini o la entropía. La característica y el umbral que minimizan la impureza se utilizan para dividir los datos en dos ramas.
Predicción: Una vez construido el árbol, se utiliza para hacer predicciones sobre datos nuevos. Los datos nuevos se introducen en el árbol, siguiendo las ramas que corresponden a las características de esos datos, hasta llegar a un nodo hoja que representa la clase predicha.
Los árboles de decisión son atractivos porque son interpretables y fáciles de visualizar. Sin embargo, pueden ser propensos al sobreajuste (overfitting), especialmente si se construyen árboles muy profundos. Para abordar este problema, se pueden utilizar técnicas como la poda (pruning) o el uso de bosques aleatorios (random forests) que combinan múltiples árboles para mejorar la precisión y reducir el sobreajuste.
En resumen, la clasificación de datos mediante árboles de decisión es una técnica poderosa y ampliamente utilizada en aprendizaje automático para tareas de clasificación, donde el objetivo es predecir la categoría o clase a la que pertenecen los datos de entrada en función de sus características.