
Duda sobre rendimiento de consulta
Publicado por Walter (4 intervenciones) el 10/11/2015 15:04:38
Buenas tardes, estoy practicando con la base de datos PUBS de SQL y tengo un ejercicio que me pide listar los libros que fueron escritos o publicados en 'California'.
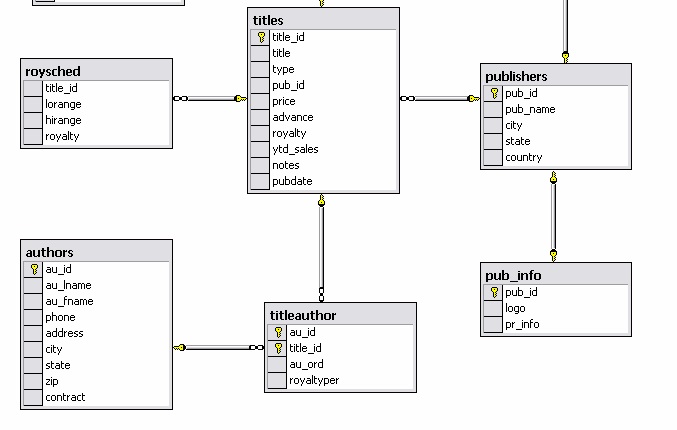
Adjunto el DER de la parte que me interesa.
Si yo ejecuto estas dos consultas
Me dan bien los resultados, pero al intentar combinar esos resultados en una sola consulta me obliga a incluir la cláusula DISTINCT ya que si no lo hago los resultados se combinan y me tira como 1000 registros.
Mi consulta es, yo pongo DISTINCT para que no me repita los resultados, pero en el fondo el rendimiento no se vería afectado? Tal vez aún no entiendo como funciona SQL internamente, a lo que voy es, al hacer esto, yo le estaría pidiendo a la Base de Datos 1000 registros pero sólo mostraría los que no se repiten? No sé si entienden a donde va mi duda. Se les ocurre otra manera de hacer la misma consulta pero de manera más eficiente o así está bien? Gracias!
Adjunto el DER de la parte que me interesa.
Si yo ejecuto estas dos consultas
1
2
3
4
5
6
7
SELECT title
FROM titles ti, titleauthor ta,authors au
WHERE ti.title_id = ta.title_id
AND ta.au_id = au.au_id
AND au.state = 'CA'
1
2
3
4
5
SELECT title
FROM titles ti,publishers pu
WHERE ti.pub_id = pu.pub_id
AND pu.state = 'CA'
Me dan bien los resultados, pero al intentar combinar esos resultados en una sola consulta me obliga a incluir la cláusula DISTINCT ya que si no lo hago los resultados se combinan y me tira como 1000 registros.
1
2
3
4
5
6
7
8
9
10
SELECT DISTINCT(title)
FROM titles ti, titleauthor ta, authors au,publishers pu
WHERE ti.title_id = ta.title_id
AND ta.au_id = au.au_id
AND au.state = 'CA'
OR ti.pub_id = pu.pub_id
AND pu.state = 'CA'
Mi consulta es, yo pongo DISTINCT para que no me repita los resultados, pero en el fondo el rendimiento no se vería afectado? Tal vez aún no entiendo como funciona SQL internamente, a lo que voy es, al hacer esto, yo le estaría pidiendo a la Base de Datos 1000 registros pero sólo mostraría los que no se repiten? No sé si entienden a donde va mi duda. Se les ocurre otra manera de hacer la misma consulta pero de manera más eficiente o así está bien? Gracias!
Valora esta pregunta

0

