
No logro descifrar el archivo original de cierto contenido de una web
Publicado por Lucas (2 intervenciones) el 28/12/2018 22:44:28
Antes que nada hola a todos y perdón si mi lenguaje no es del todo apropiado para la programación pero soy relativamente nuevo en esto.
El sitio web oficial del Mundial de Rallies provee resultados en vivo de sus carreras, entre otras cosas. Para no copiar y pegar constantemente los resultados en mi web, lo que suelo hacer es "chupar" directamente los resultados con un file_get_contents de PHP, pero para ello siempre necesito tener la url original en donde están los resultados.
Los resultados se ven en este html (https://www.wrc.com/es/wrc/livetiming/page/4175----.html) pero en realidad allí los resultados se insertan desde otros archivos, los cuales no puedo descifrar. Para que ustedes puedan ver los resultados lo pueden hacer haciendo click en los nombres de cada tramo que están en verde. Si alguno logra descifrarlo le estaré eternamente agradecido.
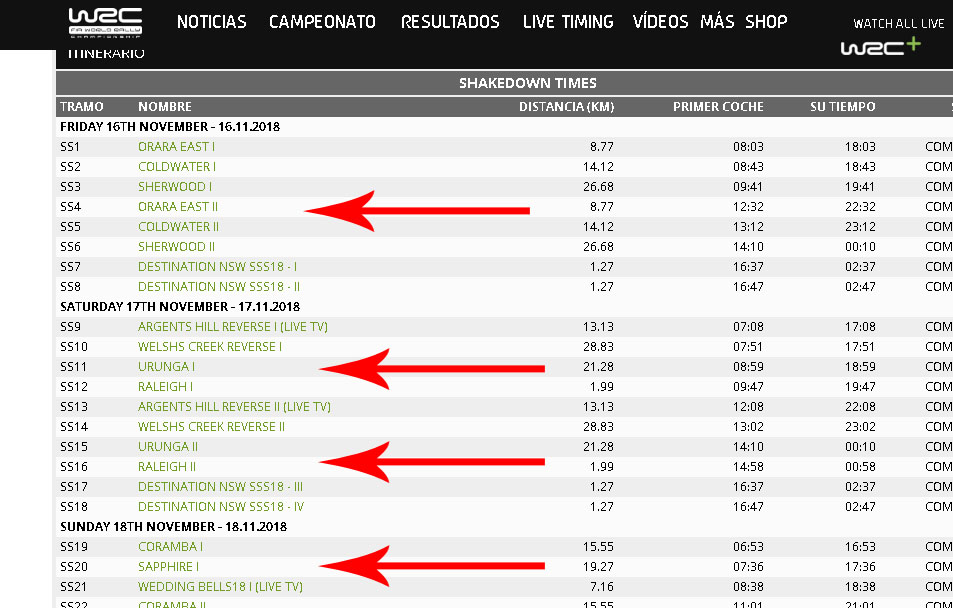
El sitio web oficial del Mundial de Rallies provee resultados en vivo de sus carreras, entre otras cosas. Para no copiar y pegar constantemente los resultados en mi web, lo que suelo hacer es "chupar" directamente los resultados con un file_get_contents de PHP, pero para ello siempre necesito tener la url original en donde están los resultados.
Los resultados se ven en este html (https://www.wrc.com/es/wrc/livetiming/page/4175----.html) pero en realidad allí los resultados se insertan desde otros archivos, los cuales no puedo descifrar. Para que ustedes puedan ver los resultados lo pueden hacer haciendo click en los nombres de cada tramo que están en verde. Si alguno logra descifrarlo le estaré eternamente agradecido.
Valora esta pregunta

0
