

Comprobacion de sintaxis en grupos de correo (RFC)
FoxPro/Visual FoxPro
Publicado el 22 de Abril del 2022 por Baldo (17 códigos)
801 visualizaciones desde el 22 de Abril del 2022
Esta rutina corresponde a una necesidad laboral. Si os sirve pues... ¡ya está hecha!
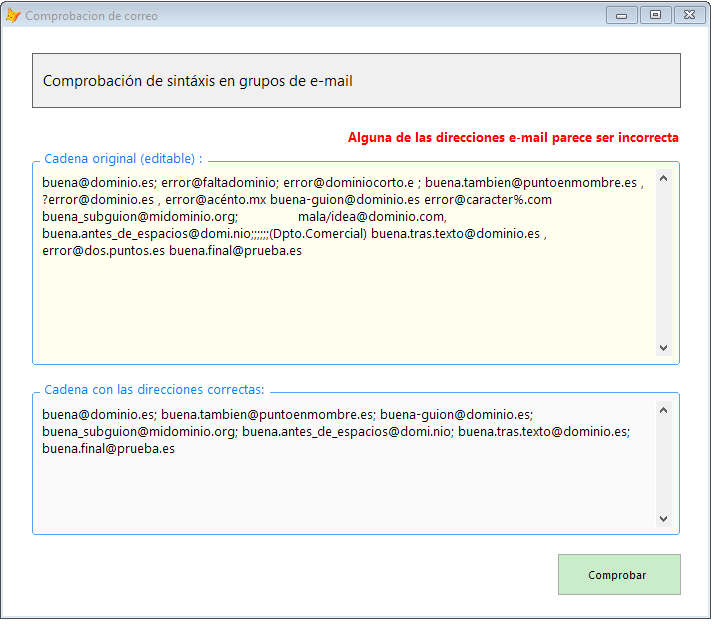
El asunto es que se puede necesitar un grupo de direcciones de correo electrónico válidas para un envío automatizado (en mi empresa se envian, por ejemplo, los pedidos a proveedor). Correos del tipo [direccion1] [direccion2]... [direccion(n)]...
El verdadero tema es que aunque se podría restringir la entrada a nivel de INPUT, hay que ser especialmente cuidadoso con la corrección en la sintaxis. Además puede que haya que tener presente que distintas rutinas pueden usar distintos separadores (Uso chilkat, por ejemplo, y el separador es "," y no ";"). Para más dificultad, uso direcciones importadas de ficheros externos...
Se hace precisa una rutina que analice el grupo de correos y conforme una cadena correcta, con el separador correcto, de direcciones correctas.
Una expresión REGEX estaría bien. Pero es un tema complicado en demasía. Lo ideal es que se pudieran discriminar direcciones correctas (del tipo [email protected]) sin que se le escape nada (una arroba y un punto al menos, y éste tras la arroba, un dominio de al menos 2 caracteres,ausencia de caracteres especiales...), que además distinga cualquier separador habitual (",",";",[TAB]) y que conforme una lista esperada por nuestra rutina. Es (muy) complicado y tema de petición de ayuda constante (https://stackoverflow.com/questions/4351349/regular-expression-for-delimited-email-address)
VFP es especialmente "plástico" a la hora de tratar cadenas... ¿Por qué no usarlo?)
Por ello he creado esta función:
mail_correcto([cadena],[separador_salida])
Tan simple como parece. Enviamos una cadena, analizamos corrección de los datos y retornamos SOLO LOS EMAIL VALIDOS separados por el [separador_salida].
Lo bueno es que ya nos podemos permitir seguir las estrictas normas (RFC2821 y RFC2822).
Teneis información en: en https://www.jochentopf.com/email/chars.html
La entrada puede tener separadores coma, punto y coma, espacios o [TAB] mezclados. Lo bueno es que al separar sólo correos, textos que me encuentro en ocasiones como "[email protected] (administración)" o similares son parseados correctamente.
Podeis echar un vistazo. Vereis una cadena de "caracteres restringidos" que podeis variar a voluntad si dado el caso (servidor UNIX, uso de caracteres especiales por alguna razón...) no necesitais filtrarlos (yo por defecto hago caso a las recomendaciones de "aunque es válido, mejor no lo uses")
Para el caso de querer simplemente COMPROBAR que los correos incluídos en la cadena son correctos (para avisar a usuario...etc) he incluído una variante que simplemente reporta un .T./.F. si algún correo no es correcto (realmente si alguna palabra no tiene pinta de correo)
mail_correcto_tf([cadena])
Adjunto un Form que simplemente lanza las rutinas para que experimenteis con ellas.
Un saludo.
El asunto es que se puede necesitar un grupo de direcciones de correo electrónico válidas para un envío automatizado (en mi empresa se envian, por ejemplo, los pedidos a proveedor). Correos del tipo [direccion1] [direccion2]... [direccion(n)]...
El verdadero tema es que aunque se podría restringir la entrada a nivel de INPUT, hay que ser especialmente cuidadoso con la corrección en la sintaxis. Además puede que haya que tener presente que distintas rutinas pueden usar distintos separadores (Uso chilkat, por ejemplo, y el separador es "," y no ";"). Para más dificultad, uso direcciones importadas de ficheros externos...
Se hace precisa una rutina que analice el grupo de correos y conforme una cadena correcta, con el separador correcto, de direcciones correctas.
Una expresión REGEX estaría bien. Pero es un tema complicado en demasía. Lo ideal es que se pudieran discriminar direcciones correctas (del tipo [email protected]) sin que se le escape nada (una arroba y un punto al menos, y éste tras la arroba, un dominio de al menos 2 caracteres,ausencia de caracteres especiales...), que además distinga cualquier separador habitual (",",";",[TAB]) y que conforme una lista esperada por nuestra rutina. Es (muy) complicado y tema de petición de ayuda constante (https://stackoverflow.com/questions/4351349/regular-expression-for-delimited-email-address)
VFP es especialmente "plástico" a la hora de tratar cadenas... ¿Por qué no usarlo?)
Por ello he creado esta función:
mail_correcto([cadena],[separador_salida])
Tan simple como parece. Enviamos una cadena, analizamos corrección de los datos y retornamos SOLO LOS EMAIL VALIDOS separados por el [separador_salida].
Lo bueno es que ya nos podemos permitir seguir las estrictas normas (RFC2821 y RFC2822).
Teneis información en: en https://www.jochentopf.com/email/chars.html
La entrada puede tener separadores coma, punto y coma, espacios o [TAB] mezclados. Lo bueno es que al separar sólo correos, textos que me encuentro en ocasiones como "[email protected] (administración)" o similares son parseados correctamente.
Podeis echar un vistazo. Vereis una cadena de "caracteres restringidos" que podeis variar a voluntad si dado el caso (servidor UNIX, uso de caracteres especiales por alguna razón...) no necesitais filtrarlos (yo por defecto hago caso a las recomendaciones de "aunque es válido, mejor no lo uses")
Para el caso de querer simplemente COMPROBAR que los correos incluídos en la cadena son correctos (para avisar a usuario...etc) he incluído una variante que simplemente reporta un .T./.F. si algún correo no es correcto (realmente si alguna palabra no tiene pinta de correo)
mail_correcto_tf([cadena])
Adjunto un Form que simplemente lanza las rutinas para que experimenteis con ellas.
Un saludo.
70 visualizaciones durante los últimos 90 días