Error al ejecutar mi script en otro ordenador
Publicado por Alberto (8 intervenciones) el 29/06/2023 01:58:42
Buenas a todos, soy nuevo en este foro y no quiero hacerles perder mucho el tiempo así que seré breve.
Tengo un script basado en python que es este codigo de aquí:
(El codigo está escrito con ayuda de chatgpt ya que no soy un experto en programacion)
Lo que hace es coger un texto especifico del pdf para después renombrar el pdf con este nombre. Luego ya podeis ver que hago menciones a otro codigos python como el de renombre2 o el de excel, pero el unico que me falla es este de aquí.
El error que tiene es que cuando me voy al ordenador del trabajo el programa no termina de ejecutar el codigo completo, como si se saltase todas las lineas que quedan y finalizase.
Llevo tiempo haciendo busquedas de cual es el problema, que si paquetes, que si la version de python, etc. Pero nada.
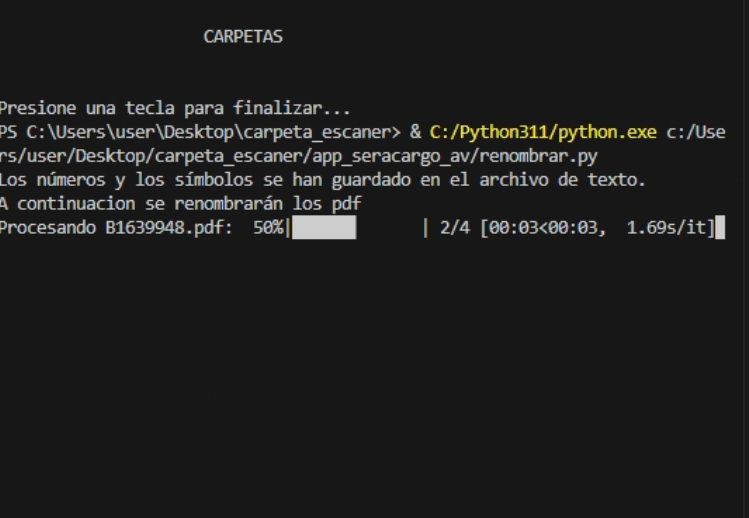
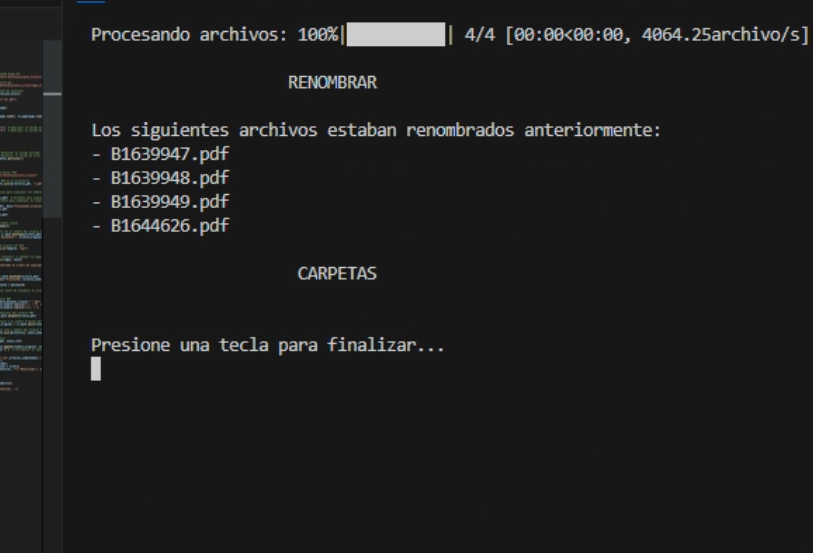
A continuación adjunto imágenes de la terminal para que veais como deberia funcionar y como lo hace:
En casa
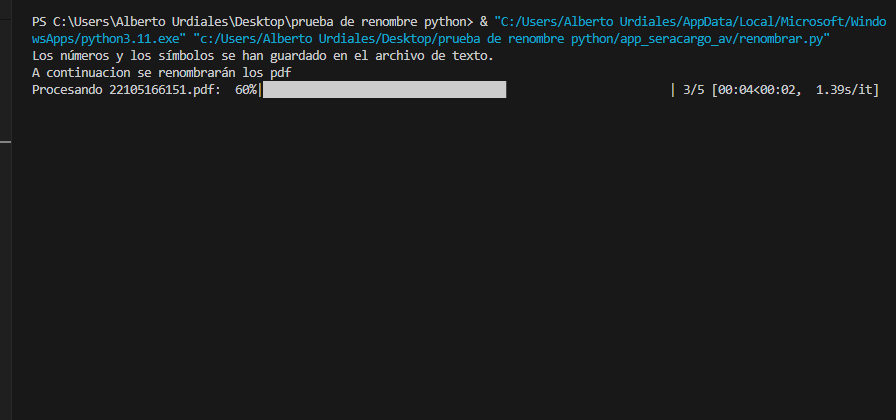
En el trabajo
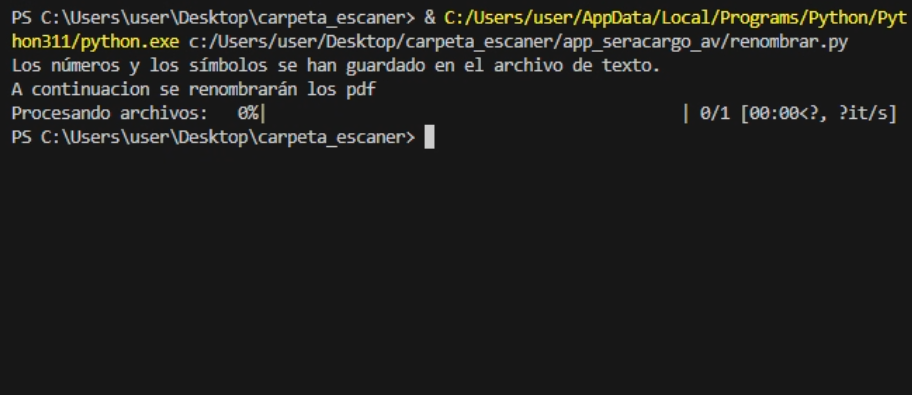
Cualquier sugerencia, que necesiteis más datos o lo que sea estaré lo más atento posible para poder contestaros cuanto antes y no haceros perder el tiempo.
Muchas gracias!
Tengo un script basado en python que es este codigo de aquí:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
import subprocess
import fitz
import ocrmypdf
import io
import glob
import re
import os
import msvcrt
from tqdm import tqdm
import sys
import time
# Ruta absoluta del archivo "EXTRACCION EXCEL.PY"ruta_extraccion_excel = r"C:\Users\Alberto Urdiales\Desktop\prueba de renombre python\app_seracargo_av\extraccion_excel.PY"
# Ruta absoluta del archivo "renombrar2.py"ruta_renombrar2 = r"C:\Users\Alberto Urdiales\Desktop\prueba de renombre python\app_seracargo_av\carpetas.py"
# Ejecutar "EXTRACCION EXCEL.PY" antes de continuarsubprocess.run(["python", ruta_extraccion_excel])
print("A continuacion se renombrarán los pdf")
time.sleep(4) # espera en segundos
def escanear_pagina_ocr(page, language):
src = page.parent
doc = fitz.open()
doc.insert_pdf(src, from_page=page.number, to_page=page.number)
pdfbytes = doc.tobytes()
inbytes = io.BytesIO(pdfbytes)
outbytes = io.BytesIO()
sys.stdout = open(os.devnull, "w") # Redirigir la salida estándar a os.devnull
sys.stderr = open(os.devnull, "w") # Redirigir la salida de error a os.devnull
ocrmypdf.ocr(
inbytes, outbytes,language=language,
output_type="pdf",
force_ocr=True )sys.stdout = sys.__stdout__ # Restaurar la salida estándar
sys.stderr = sys.__stderr__ # Restaurar la salida de error
ocr_pdf = fitz.open("pdf", outbytes.getvalue())
text = ocr_pdf[0].get_text()
return text
if __name__ == "__main__":
# Directorio que contiene los archivos PDFdirectorio_pdf = r"C:\Users\Alberto Urdiales\Desktop\prueba de renombre python"
# Obtener la lista de archivos PDF en el directorioarchivos_pdf = glob.glob(os.path.join(directorio_pdf, "*.pdf"))
regex = r"N740[-\s]*([^\s-]+)"
archivos_renombrados = [] # Lista para almacenar los nombres de los archivos renombrados y sus nombres anteriores
archivos_totales = len(archivos_pdf) # Variable para almacenar el número total de documentos
archivos_completados = 0 # Variable para almacenar el número de documentos completados con éxito
with tqdm(total=len(archivos_pdf), desc="Procesando archivos") as pbar:
for archivo_pdf in archivos_pdf: # Abrir el documentodoc = fitz.open(archivo_pdf)
try: # Cargar solo la primera páginapagina = doc.load_page(1)
except: # Crear una variable con el nombre del archivo e indicar que hay un error por falta de documentaciónarchivo_original = os.path.basename(archivo_pdf)
print("\nERROR, el documento:", archivo_original, "no es correcto o está incompleto.\nCompruebe que su documentación contenga todas las hojas necesarias para extraer la información")
break
# Obtener el texto de la página con OCRtexto = escanear_pagina_ocr(pagina, "spa")
try: # Buscar la cadena "Cliente:" y obtener la siguiente palabramatches = re.findall(regex, texto)
except:print("No se ha encontrado el número de conocimiento")
break
if matches:archivo_nombre = os.path.basename(archivo_pdf) # Obtener solo el nombre del archivo de la ruta absoluta
pbar.set_description(f"Procesando {archivo_nombre}")
pbar.update(1)
palabra_despues_cliente = matches[0]
# Cerrar el documento antes de renombrar el archivodoc.close()
# Renombrar el archivo PDFnuevo_nombre = palabra_despues_cliente + ".pdf"
nuevo_nombre = nuevo_nombre.replace("/", "_") # Reemplazar "/" por "_" para evitar problemas en el nombre del archivo
nuevo_nombre = nuevo_nombre.replace("\\", "_") # Reemplazar "\" por "_" para evitar problemas en el nombre del archivo
# Obtener la ruta absoluta del archivo PDFruta_absoluta = os.path.abspath(archivo_pdf)
# Obtener el directorio y el nombre original del archivo PDFdirectorio, nombre_original = os.path.split(ruta_absoluta)
# Construir la nueva ruta y nombre del archivo PDFnueva_ruta = os.path.join(directorio, nuevo_nombre)
# Renombrar el archivoos.rename(archivo_pdf, nueva_ruta)
archivos_renombrados.append((nombre_original, nuevo_nombre)) # Agregar el nombre anterior y el nombre actual a la lista de archivos renombrados
archivos_completados += 1 # Incrementar el contador de documentos completados con éxito
os.system("cls") # Limpiar la terminal en Windows
print("El proceso ha finalizado con",archivos_completados,"/",archivos_totales)
print("\nArchivos renombrados:")
for archivo in archivos_renombrados:nombre_anterior, nombre_actual = archivo
print("Original:", nombre_anterior, ">>> Modificado:", nombre_actual)
break
print("")
# Ejecutar "renombrar2.py"subprocess.run(["python", ruta_renombrar2])
print("\nPresione una tecla para finalizar...")
msvcrt.getch()
(El codigo está escrito con ayuda de chatgpt ya que no soy un experto en programacion)
Lo que hace es coger un texto especifico del pdf para después renombrar el pdf con este nombre. Luego ya podeis ver que hago menciones a otro codigos python como el de renombre2 o el de excel, pero el unico que me falla es este de aquí.
El error que tiene es que cuando me voy al ordenador del trabajo el programa no termina de ejecutar el codigo completo, como si se saltase todas las lineas que quedan y finalizase.
Llevo tiempo haciendo busquedas de cual es el problema, que si paquetes, que si la version de python, etc. Pero nada.
A continuación adjunto imágenes de la terminal para que veais como deberia funcionar y como lo hace:
En casa
En el trabajo
Cualquier sugerencia, que necesiteis más datos o lo que sea estaré lo más atento posible para poder contestaros cuanto antes y no haceros perder el tiempo.
Muchas gracias!
Valora esta pregunta

0