Mostrando del 51 al 60 de 131 registros
(Artículo pseudo-profético escrito por Wes McKinney en 2011)
En este documento hablaremos de pandas, una biblioteca de Python de estructuras y herramientas de datos enriquecidos para trabajar con conjuntos de datos estructurados comunes a estadísticas, finanzas, ciencias sociales y muchos otros campos. La biblioteca proporciona rutinas integradas e intuitivas para realizar manipulaciones y análisis de datos comunes en dichos conjuntos de datos.
El análisis de datos está en furor, y Python-pandas no deja de ganar popularidad, y cada vez más.

Todas las librerías para desarrollar aplicaciones de escritorio trabajan con un bucle principal que se ocupa de manejar eventos tales como mostrar la ventana en la pantalla, moverla, redimensionarla, responder a la presión de un botón; en general, toda interacción con la interfaz. Algunos de esos eventos acaso estarán asociados con una función que proporcionamos nosotros; por ejemplo, un método button1_pressed() que es invocado por dicha librería cuando el usuario presiona el control button1. Cuando trabajamos con Qt, la forma de responder a esos eventos es típicamente conectar una señal con un slot.
El problema surge cuando, en respuesta a alguno de esos eventos o bien durante la creación de la interfaz, ejecutamos una operación cuya duración no es despreciable (podríamos decir que cualquier tarea que tarde más de un segundo deja de ser despreciable). Esto hace que el procesador esté ocupado ejecutando nuestra tarea y no pueda atender al bucle principal de la aplicación; por ende, la interfaz deja de responder: no podemos moverla, cerrarla, redimensionarla, ni efectuar cualquier otro tipo de interacción con ella.

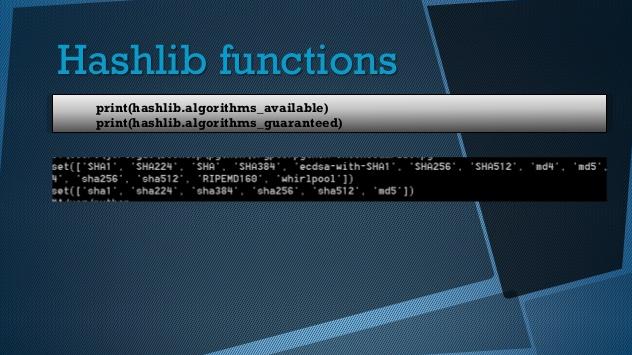
Actualmente cualquier proyecto que requiera el almacenamiento de datos de un usuario hace uso de uno o múltiples algoritmos para llevar a cabo un cifrado, que permite ocultar o proteger determinada información. En la mayoría de los sitios que requieren de un registro las contraseñas son cifradas y se almacena un hash (el resultado) en lugar del texto original.
Existen diversos y muy variados algoritmos para realizar dicha acción; esta entrada cubre la utilización del MD5 (Message-Digest Algorithm 5) y las familias SHA (Secure Hash Algorithm), BLAKE y SHAKE.
En algunas ocasiones nos encontraremos con datos que siguen una función polinómica. En estos casos, el mejor modelo que podemos usar es la regresión polinómica. Este artículo explica la teoría detrás de la regresión polinómica y cómo usarla en python.
Índice de Contenidos:
1.- Regresión Polinómica – Teoría
2.- ¿Cómo hacer una Regresión Polinómica en Python?
2.1.- Datos de ejemplo
2.2.- Construyendo un modelo de Regresión Polinómica en Python
2.3.- Evaluación del modelo
3.- Resumen
4.- Recursos

Antes de empezar tengo que advertirte que ningún lenguaje de programación, por simple que sea, puede aprenderse en profundidad en tan poco tiempo, a no ser que se requiera de experiencia previa en otros lenguajes. Dominar la programación precisa de experiencia, lo cual a su vez requiere de un tiempo mínimo que permita afianzar las estructuras mentales necesarias para entender la secuencia lógica a seguir para desarrollar un programa o proyecto de software.
El objetivo de este artículo no es enseñar a programar, sino tratar de exponer en 10 minutos los elementos más importantes del lenguaje Python, sería algo así como una mezcla entre un tutorial y una cheatsheet. Haré uso de una REPL para exponer los ejemplos, con lo que podrás modificar y jugar con ellos sin tener que salir de la entrada. Es totalmente recomendable seguir el artículo en un ordenador o tablet, ya que la REPL por limitaciones de espacio no es tan cómoda de utilizar en un móvil.

 Python - Introducción a buenas prácticas de programación
Python - Introducción a buenas prácticas de programación


