Generador de gifs a partir de video (nueva version)
Python
 (1)
(1)Actualizado el 10 de Julio del 2026 por Antonio (77 códigos) (Publicado el 29 de Enero del 2024)
26.588 visualizaciones desde el 29 de Enero del 2024
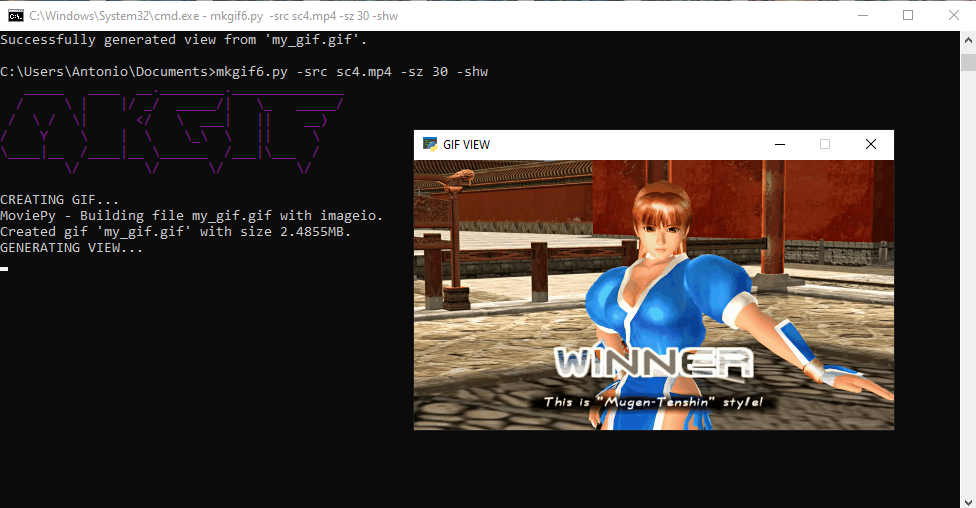
Programa para generar gifs animados a partir de vídeos, que se ejecuta en la línea de comandos.
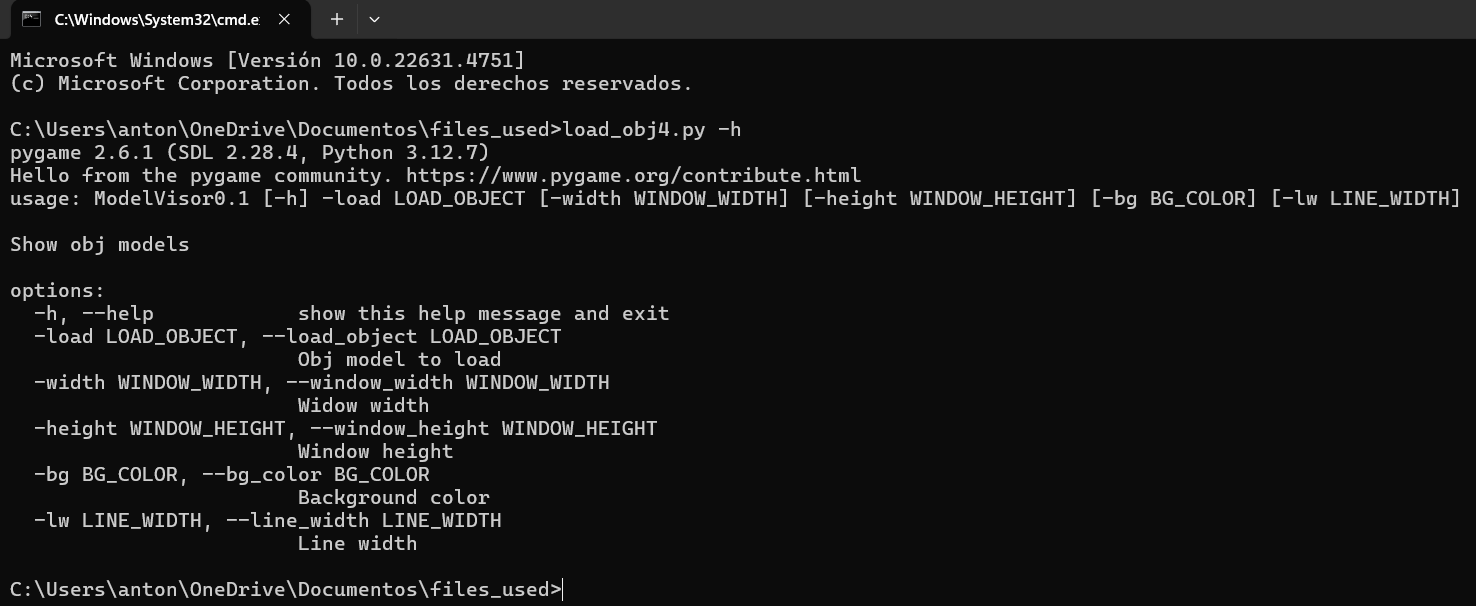
ARGUMENTOS:
-src/--source: Nombre del vídeo original (obligatorio).
-dest/--destination: Nombre del archivo a generar (opcional).
-sz/--size: Tamaño en porcentaje del gif respecto al vídeo original (opcional).
-shw/--show: Muestra resultado en ventana emergente al finalizar el proceso de generado (opcional).
-st/--start: Segundo inicial para gif (opcional).
-e/--end: Segundo final (opcional).
-spd/--speed: Velocidad relativa de la animación (opcional)
PARA CUALQUIER DUDA U OBSERVACIÓN, USEN LA SECCIÓN DE COMENTARIOS.
ARGUMENTOS:
-src/--source: Nombre del vídeo original (obligatorio).
-dest/--destination: Nombre del archivo a generar (opcional).
-sz/--size: Tamaño en porcentaje del gif respecto al vídeo original (opcional).
-shw/--show: Muestra resultado en ventana emergente al finalizar el proceso de generado (opcional).
-st/--start: Segundo inicial para gif (opcional).
-e/--end: Segundo final (opcional).
-spd/--speed: Velocidad relativa de la animación (opcional)
PARA CUALQUIER DUDA U OBSERVACIÓN, USEN LA SECCIÓN DE COMENTARIOS.