
Problema con analisis de datos
Publicado por Poeta (1 intervención) el 07/07/2020 16:01:04
Estoy tratando de hacer analisis de sentimientos de un texto. (una columna particular) pero estoy teniendo problas aun utilizando este modelo (https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment#)
Se agradece cualquier orientación tengo un dataset de 250K filas y 21 columnas (calculo que en una semana o dos tendre un 1Millon da columnas y sera más complicado todo, por lo que espero tener limpio el codigo para hacerlo....cuando tenia menos de 100K columnas utilizaba Orange pero por la RAM ya no safa, así que lo estoy haciendo en Jupyter y con modelos ya establecidos....en fin agradezco toda la ayuda posible.
ERROR:
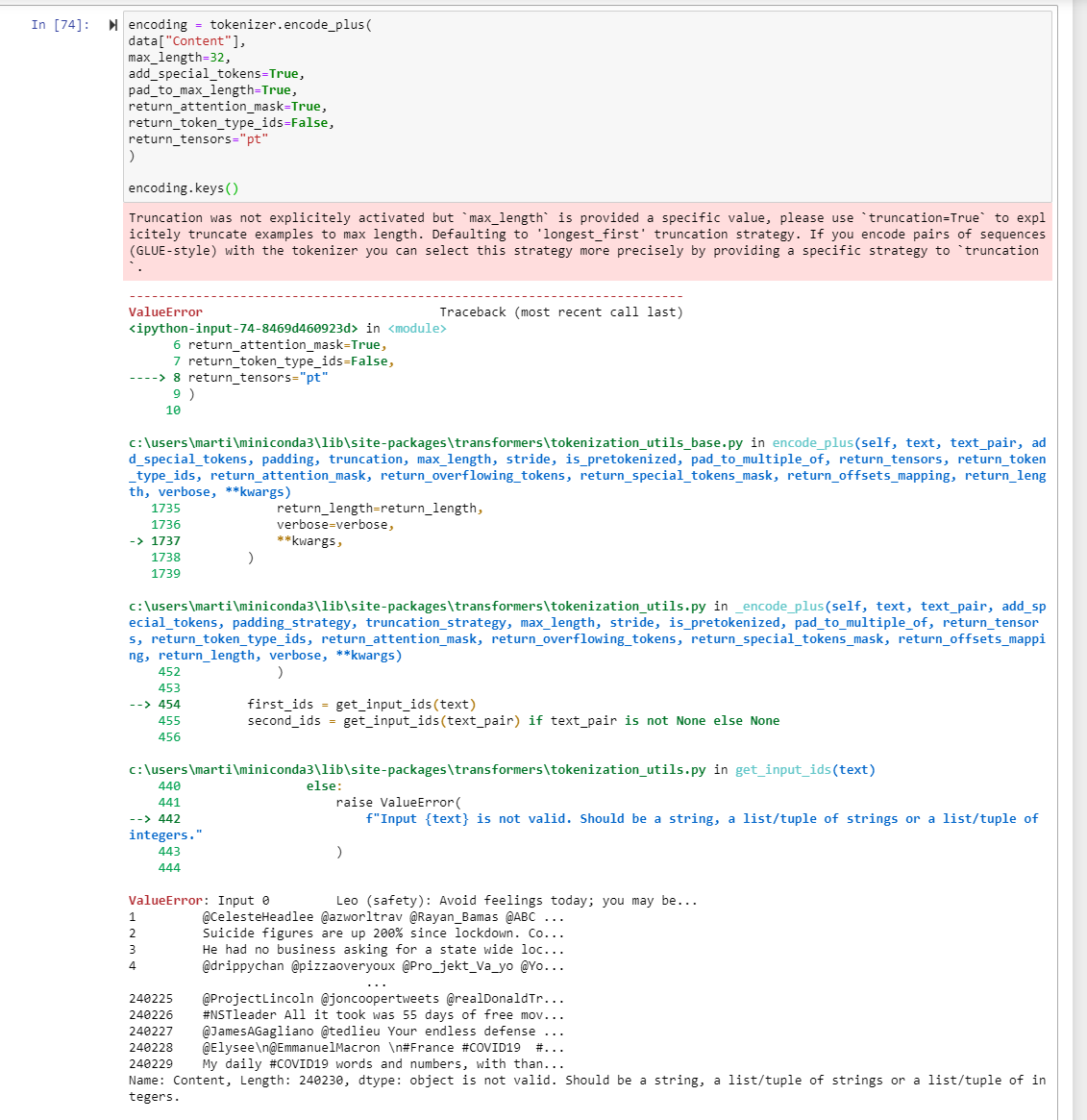
Truncation was not explicitely activated but `max_length` is provided a specific value, please use `truncation=True` to explicitely truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation
Se agradece cualquier orientación tengo un dataset de 250K filas y 21 columnas (calculo que en una semana o dos tendre un 1Millon da columnas y sera más complicado todo, por lo que espero tener limpio el codigo para hacerlo....cuando tenia menos de 100K columnas utilizaba Orange pero por la RAM ya no safa, así que lo estoy haciendo en Jupyter y con modelos ya establecidos....en fin agradezco toda la ayuda posible.
1
2
3
4
5
6
7
8
9
10
11
encoding = tokenizer.encode_plus(
data["Content"],
max_length=32,
add_special_tokens=True,
pad_to_max_length=True,
return_attention_mask=True,
return_token_type_ids=False,
return_tensors="pt"
)encoding.keys()
ERROR:
Truncation was not explicitely activated but `max_length` is provided a specific value, please use `truncation=True` to explicitely truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation
Valora esta pregunta

0