Descenso de Gradiente Estocástico(SGD)
Python
Publicado el 13 de Septiembre del 2023 por Hilario (145 códigos)
582 visualizaciones desde el 13 de Septiembre del 2023
[b]AulaF_658-Gradiente_Estocastico.py
*************************************************[/b]
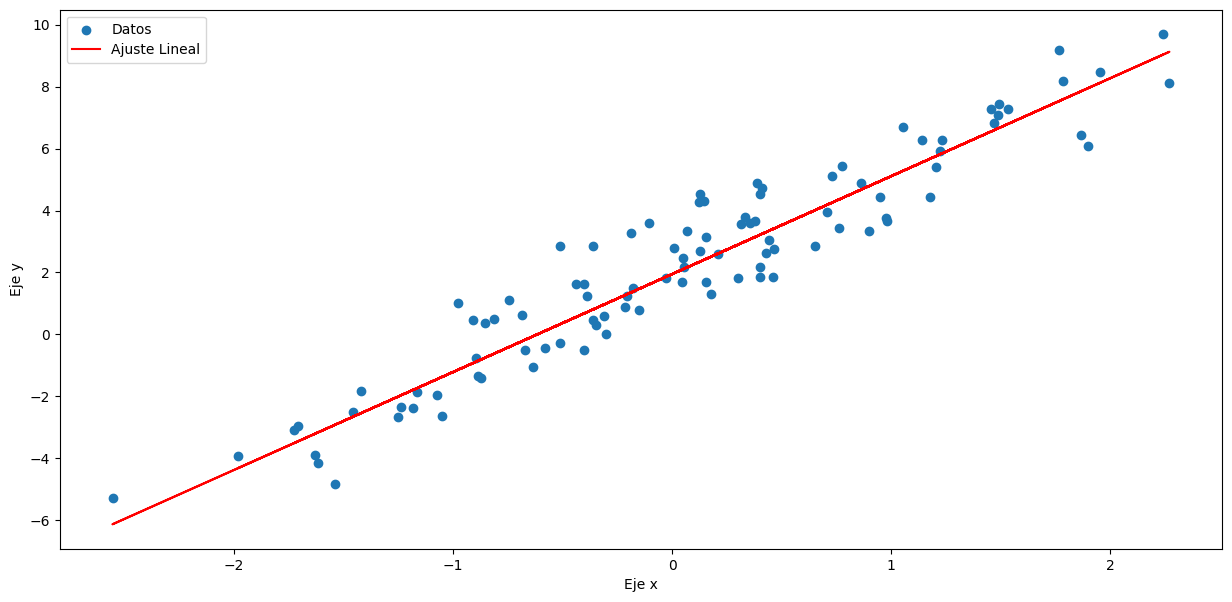
El descenso de gradiente estocástico (SGD por sus siglas en inglés, Stochastic Gradient Descent) es un algoritmo de optimización ampliamente utilizado en el campo del aprendizaje automático y la inteligencia artificial para entrenar modelos de machine learning, especialmente en el contexto de aprendizaje profundo (deep learning). SGD es una variante del algoritmo de descenso de gradiente clásico.
La principal diferencia entre el descenso de gradiente estocástico y el descenso de gradiente tradicional radica en cómo se actualizan los parámetros del modelo durante el proceso de entrenamiento. En el descenso de gradiente tradicional, se calcula el gradiente de la función de pérdida utilizando todo el conjunto de datos de entrenamiento en cada paso de la optimización, lo que puede ser computacionalmente costoso en conjuntos de datos grandes.
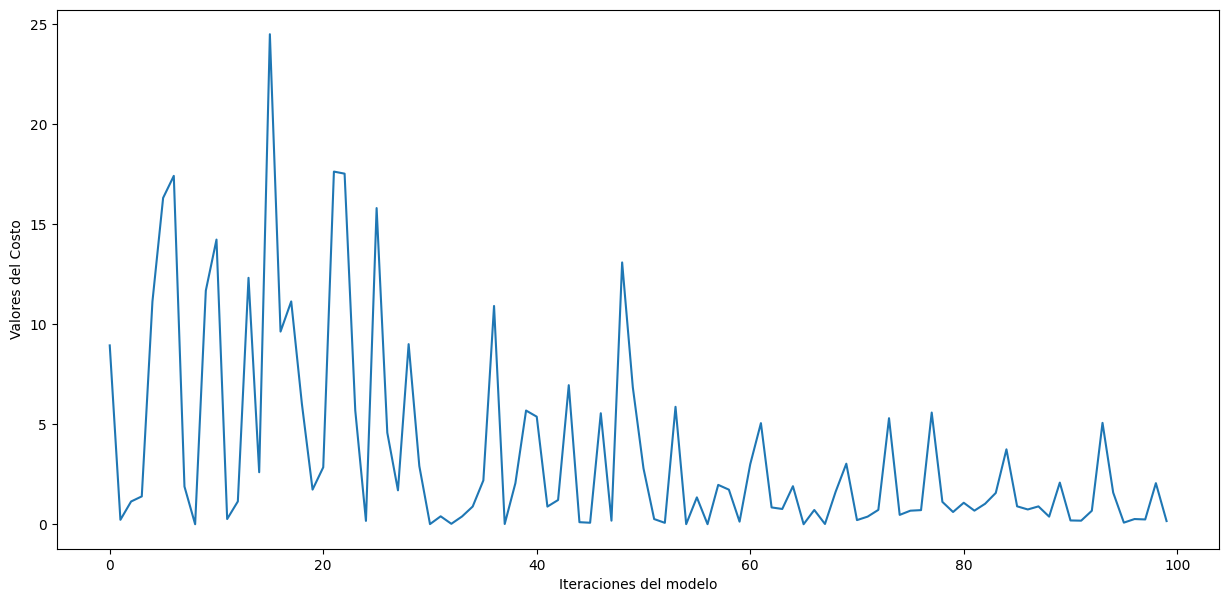
En contraste, en SGD, en cada paso de optimización se utiliza un único ejemplo de entrenamiento (o un pequeño lote de ejemplos de entrenamiento) de forma aleatoria. Esto introduce estocasticidad en el proceso, ya que el gradiente calculado en cada paso se basa en una muestra aleatoria de datos. Como resultado, el proceso de optimización es más rápido y puede converger a un mínimo local o global de la función de pérdida de manera más eficiente en muchos casos.
Los pasos generales del algoritmo de descenso de gradiente estocástico son los siguientes:
Inicializar los parámetros del modelo de manera aleatoria o utilizando algún valor inicial.
Mezclar aleatoriamente el conjunto de datos de entrenamiento.
Realizar iteraciones sobre el conjunto de datos de entrenamiento, tomando un ejemplo (o un pequeño lote) a la vez.
Calcular el gradiente de la función de pérdida con respecto a los parámetros utilizando el ejemplo seleccionado.
Actualizar los parámetros del modelo utilizando el gradiente calculado y una tasa de aprendizaje predefinida.
Repetir los pasos 3-5 durante un número fijo de iteraciones o hasta que se cumpla un criterio de convergencia.
El uso de SGD es beneficioso en situaciones donde el conjunto de datos es grande o cuando se necesita un entrenamiento rápido. Sin embargo, la estocasticidad puede hacer que el proceso sea más ruidoso y requiera una sintonización cuidadosa de hiperparámetros, como la tasa de aprendizaje. Además, existen variantes de SGD, como el Mini-Batch Gradient Descent, que toman un pequeño lote de ejemplos en lugar de uno solo, lo que ayuda a suavizar las actualizaciones de parámetros sin la necesidad de calcular el gradiente en todo el conjunto de datos.
*************************************************[/b]
La principal diferencia entre el descenso de gradiente estocástico y el descenso de gradiente tradicional radica en cómo se actualizan los parámetros del modelo durante el proceso de entrenamiento. En el descenso de gradiente tradicional, se calcula el gradiente de la función de pérdida utilizando todo el conjunto de datos de entrenamiento en cada paso de la optimización, lo que puede ser computacionalmente costoso en conjuntos de datos grandes.
En contraste, en SGD, en cada paso de optimización se utiliza un único ejemplo de entrenamiento (o un pequeño lote de ejemplos de entrenamiento) de forma aleatoria. Esto introduce estocasticidad en el proceso, ya que el gradiente calculado en cada paso se basa en una muestra aleatoria de datos. Como resultado, el proceso de optimización es más rápido y puede converger a un mínimo local o global de la función de pérdida de manera más eficiente en muchos casos.
Los pasos generales del algoritmo de descenso de gradiente estocástico son los siguientes:
Inicializar los parámetros del modelo de manera aleatoria o utilizando algún valor inicial.
Mezclar aleatoriamente el conjunto de datos de entrenamiento.
Realizar iteraciones sobre el conjunto de datos de entrenamiento, tomando un ejemplo (o un pequeño lote) a la vez.
Calcular el gradiente de la función de pérdida con respecto a los parámetros utilizando el ejemplo seleccionado.
Actualizar los parámetros del modelo utilizando el gradiente calculado y una tasa de aprendizaje predefinida.
Repetir los pasos 3-5 durante un número fijo de iteraciones o hasta que se cumpla un criterio de convergencia.
El uso de SGD es beneficioso en situaciones donde el conjunto de datos es grande o cuando se necesita un entrenamiento rápido. Sin embargo, la estocasticidad puede hacer que el proceso sea más ruidoso y requiera una sintonización cuidadosa de hiperparámetros, como la tasa de aprendizaje. Además, existen variantes de SGD, como el Mini-Batch Gradient Descent, que toman un pequeño lote de ejemplos en lugar de uno solo, lo que ayuda a suavizar las actualizaciones de parámetros sin la necesidad de calcular el gradiente en todo el conjunto de datos.