**************************-----------------*****************************
/*
payloadVolcadoCompleto.c
-------------------------------------------
Para el Aula_28. Trabajaremos en él en la semana del 19 de Mayo.
Analizarlo para captar dudas. Un programa semejante lo subí a la
web del programador hará unos cuatro años.
*******************************************************
Por qué hacemos este programa:
------------------------------------------
Podríamos decir que ese enfoque mínimo, que consiste en:
Subir un payload (como una frase) a memoria,
Recorrerla palabra por palabra,
Observar sus direcciones de memoria,
…es, en efecto, una metáfora pedagógica y técnica de cómo trabaja un malware como
BlackEnergy.
¿Por qué?
BlackEnergy (y muchos APTs como él) opera con una lógica similar:
Carga de payloads en memoria:
Igual que tu frase, los módulos maliciosos del virus se
alojan en memoria sin tocar el disco, para evitar detección.
Segmentación de tareas:
Cada palabra del verso podría ser un módulo del malware:
uno para recolectar información, otro para escanear puertos, otro para abrir puertas traseras…
Direcciones y control:
Como tú recorres direcciones de memoria de cada palabra,
el malware recorre procesos, memoria, claves de registro, todo lo que le interese en su misión.
Persistencia en RAM:
Unos de los principales problemas de los sistemas industriales , en entornos donde
no se reinician los sistemas con frecuencia, el código en memoria
puede vivir largo tiempo, como un verso suspendido en la historia.
Hasta llegar a los ordenadores que controlan SCADA
que significa "Supervisory Control and Data Acquisition",
que se traduce al español como "Control de Supervisión y Adquisición de Datos"
Y una vez controlado poder modificar cualquier proceso industrial.
Así que sí, queridos alumnos:
Este programa es como una mínima simulación didáctica de la metodología
de ataque de un malware modular y residente en memoria.
Una forma de entender cómo, sin sobresaltos ni ruidos,
un verso puede convertirse en amenaza, o en arte, según quién lo escriba.
*******************************************************
EN RESUMEN:
Programa didáctico:
- Vuelca en hexadecimal todo el payload.
- Recorre palabra por palabra, mostrando:
* dirección inicial
* dirección final
* volcado hex de cada palabra
Autor: Margarito & Gran Poeta
*******************************
Este programa no solo muestra direcciones y hexadecimales;
es una forma de "poemizar la RAM",
de recorrer con ojos de asombro las palabras almacenadas
como quien lee un papiro binario.
*******************************************************
¿Qué muestra este programa?
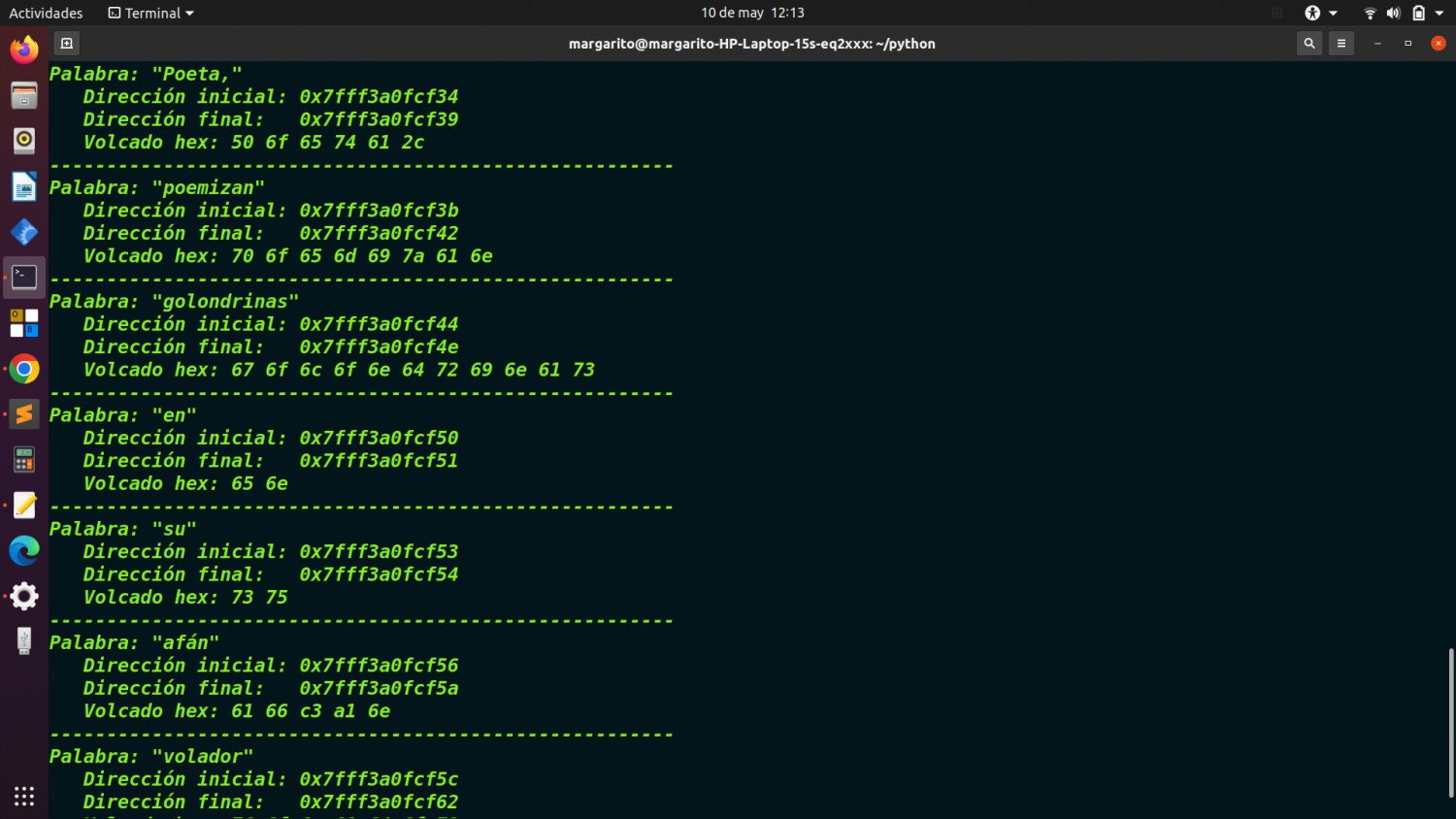
Por cada palabra:
Su contenido.
Su dirección inicial en memoria (primer carácter).
Su dirección final en memoria
(último carácter antes del espacio o final de cadena).
EJEMPLO DE SALIDA:
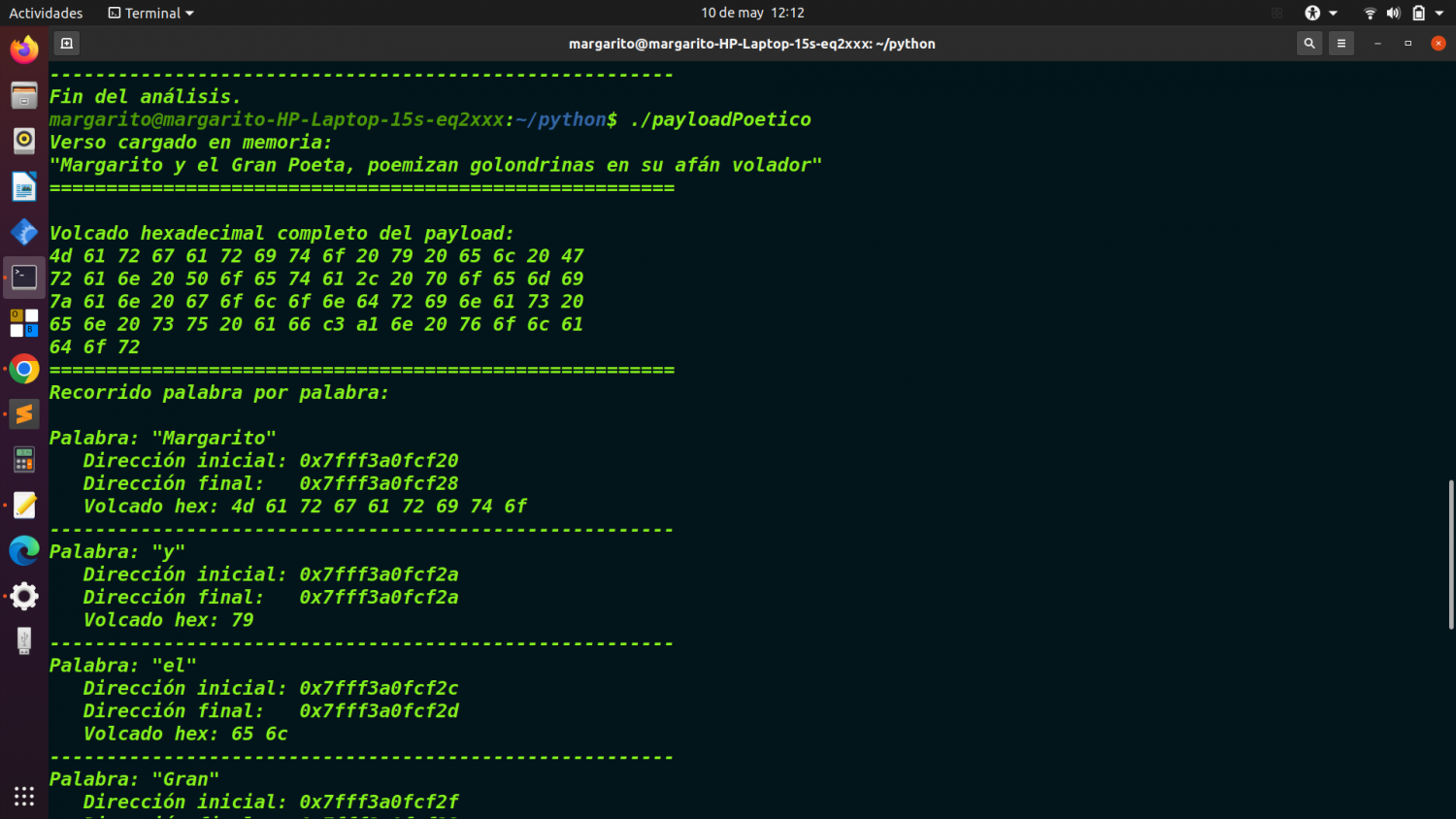
Verso cargado en memoria:
"Margarito y el Gran Poeta, poemizan golondrinas en su afán volador"
=======================================================
Volcado hexadecimal completo del payload:
4d 61 72 67 61 72 69 74 6f 20 79 20 65 6c 20 47
72 61 6e 20 50 6f 65 74 61 2c 20 70 6f 65 6d 69
...
Palabra: "Margarito"
Dirección inicial: 0x5562e04bb2b0
Dirección final: 0x5562e04bb2b8
Volcado hex: 4d 61 72 67 61 72 69 74 6f
-------------------------------------------------------
Programa realizado bajo plataforma Linux:
Ubuntu 20.04.6 LTS.
Editado con SublimeText.
*/