

Árbol hash de Merkle.
Python
Publicado el 1 de Marzo del 2025 por Hilario (145 códigos)
1.840 visualizaciones desde el 1 de Marzo del 2025
----------------------------------------------------------------------------------
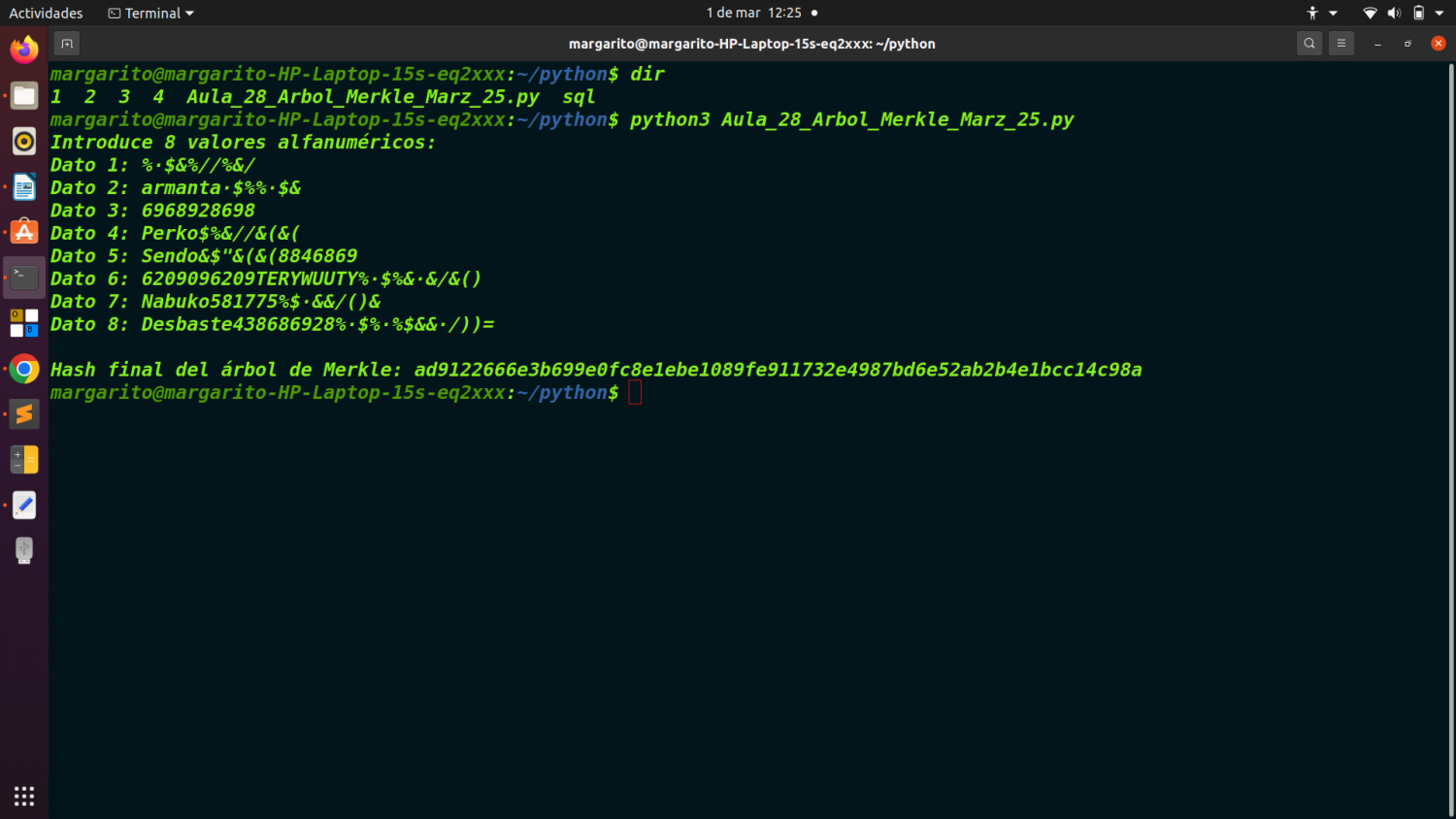
python3 Aula_28_Arbol_Merkle_Marz_25.py
---------------------------------------
Problema, para el Aula 28, a estudiar por partes en la primera semana de Marzo/25.
***********************************************************************************************
Vamos a plantear hoy un clásico problema, muy habitual en la criptomoneda Bitcoin, donde se aplica el arbol de Merkle, para optener el hash final de las transaciones pertenecientes a un bloke, este dato es uno de los fundamentales con el fin de poder proceder a su minado.
Plantearemos el problema resumido de la siguiente forma:
Queremos desarrollar un arbol de Merkle, en python, en sistema operativo Ubuntu. Necesitamos que las entradas del árbol sean de 8 opciones por consola.Las entradas deben admitir datos alfanumericos. Deberemos optener el hash final del resultado del arbol, de los datos introducidos. El lenguaje que vamos a aplicar es python3, bajo un istema operativo linux ubuntu, trabajando en consola.
**************************************************
Inicialmente vamos a definir, para entenderlo, que es un árbol de Merkle.
------------------------------------------------------------------------
Bien. Decimos que un árbol de Merkle es una estructura de datos en forma de árbol binario que se usa para verificar la integridad y autenticidad de los datos de manera eficiente.
Se utiliza en criptografía, sistemas de archivos distribuidos, y , como hemos indicado antes, en los blockchain para asegurar que la información no ha sido alterada.
El aula, deberá profundizar un poco más en esta definición, con el fin de comprender su significado.
***************************************************************************************************
Este programa fue desarrollado con Python V3.
Editado con Sublime Text.
Bajo una plataforma Linux,
Ubuntu 20.04.6 LTS.
Ejecución bajo este comado en consola:
python3 Aula_28_Arbol_Merkle_Marz_25.py
**********************************************
EXPLICACION DE LOS PASOS DEL EJERCICIO PHYTHON.
------------------------------------------------------------------------------
1️⃣ Importación de Módulos de módulos
--------------------------------------
necesario para el desarrollo de python.
import hashlib
import networkx as nx
import matplotlib.pyplot as plt
hashlib: Se usa para calcular los hashes SHA-256 de los datos.
networkx: Permite crear y visualizar grafos (en este caso, el árbol de Merkle).
matplotlib.pyplot: Se usa para graficar el árbol de Merkle.
2️⃣ Función para Calcular el Hash de un Dato
---------------------------------------------
def hash_data(data):
return hashlib.sha256(data.encode()).hexdigest()
Recibe un data (cadena de texto).
Usa SHA-256 para calcular su hash hexadecimal y lo devuelve.
3️⃣ Construcción del Árbol de Merkle
------------------------------------
def merkle_tree_hash(data_list):
if len(data_list) % 2 != 0:
data_list.append(data_list[-1]) # Duplicar el último si es impar
Si la cantidad de datos es impar, se duplica el último dato para asegurar que haya pares.
hashes = [hash_data(data) for data in data_list]
tree_levels = [hashes]
Se generan los hashes SHA-256 de cada dato y se almacenan en la primera capa del árbol.
while len(hashes) > 1:
temp_hashes = []
for i in range(0, len(hashes), 2):
combined_hash = hash_data(hashes[i] + hashes[i + 1])
temp_hashes.append(combined_hash)
hashes = temp_hashes
tree_levels.append(hashes)
Se combinan de dos en dos, se concatenan y se vuelven a hashear hasta llegar a un único hash raíz.
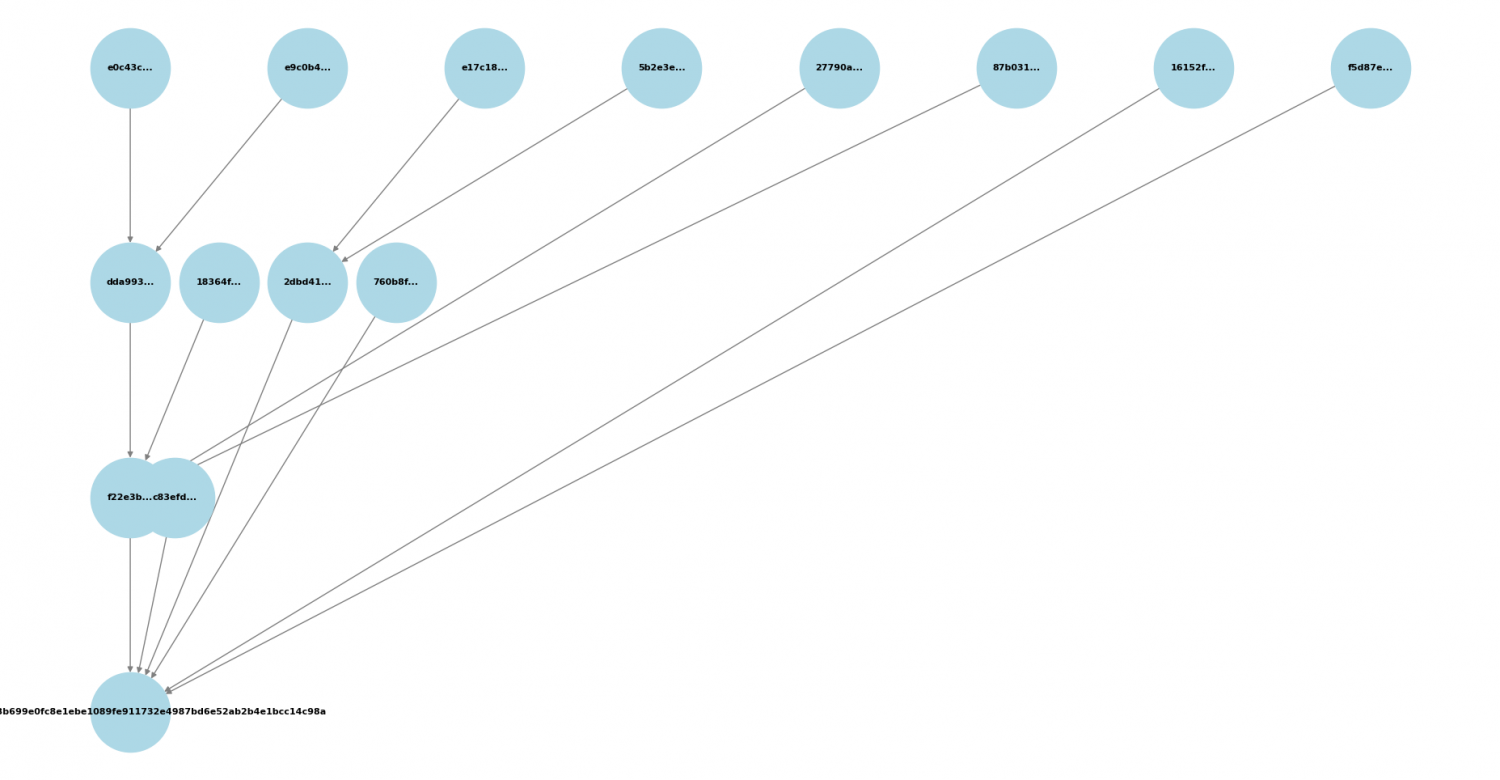
Ejemplo de construcción:
Entradas: A, B, C, D, E, F, G, H
Nivel 0: hash(A), hash(B), hash(C), hash(D), hash(E), hash(F), hash(G), hash(H)
Nivel 1: hash(hash(A)+hash(B)), hash(hash(C)+hash(D)), hash(hash(E)+hash(F)), hash(hash(G)+hash(H))
Nivel 2: hash(hash_AB + hash_CD), hash(hash_EF + hash_GH)
Nivel 3 (Raíz): hash(hash_ABCD + hash_EFGH)
4️⃣ Dibujar el Árbol de Merkle
--------------------------------
def plot_merkle_tree(tree_levels):
G = nx.DiGraph()
pos = {}
level_offset = 2.5
node_id = 0
Se crea un grafo dirigido G para representar el árbol.
pos almacena las posiciones de los nodos.
level_offset controla la separación vertical de los niveles.
for level, nodes in enumerate(tree_levels):
y_pos = -level * level_offset
x_step = 2 ** (len(tree_levels) - level - 1)
for i, node in enumerate(nodes):
label = node if level == len(tree_levels) - 1 else node[:6] + "..."
pos[node_id] = (i * x_step, y_pos)
G.add_node(node_id, label=label)
node_id += 1
Se añaden nodos con etiquetas:
Se muestran solo los primeros 6 caracteres seguidos de ..., excepto en el hash final.
node_id = 0
for level in range(len(tree_levels) - 1):
for i in range(0, len(tree_levels[level]), 2):
parent_id = node_id + len(tree_levels[level])
G.add_edge(node_id, parent_id)
G.add_edge(node_id + 1, parent_id)
node_id += 2
Se añaden las conexiones entre nodos padre e hijos.
labels = nx.get_node_attributes(G, 'label')
plt.figure(figsize=(15, 10))
nx.draw(G, pos, with_labels=True, labels=labels, node_size=5000, node_color='lightblue', font_size=8, font_weight='bold', edge_color='gray')
plt.title("Árbol de Merkle", fontsize=14)
plt.show()
Se genera la gráfica con matplotlib, usando networkx para dibujar el árbol.
5️⃣ Función Principal
----------------------
def main():
print("Introduce 8 valores alfanuméricos:")
data_list = [input(f"Dato {i+1}: ") for i in range(8)]
Se piden 8 entradas de datos por consola.
tree_levels = merkle_tree_hash(data_list)
root_hash = tree_levels[-1][0]
print("\nHash final del árbol de Merkle:", root_hash)
Se construye el árbol de Merkle.
Se imprime el hash raíz (Merkle Root).
plot_merkle_tree(tree_levels)
Se dibuja la gráfica del árbol.
6️⃣ Ejecución del Programa
----------------------------
if __name__ == "__main__":
main()
Se ejecuta main() solo si el script se ejecuta directamente.



