
GOOGLE COLAB
Python
Actualizado el 19 de Julio del 2023 por Hilario (122 códigos) (Publicado el 13 de Julio del 2023)
1.727 visualizaciones desde el 13 de Julio del 2023
Ad augusta per angusta
**********************************************************************
Hilario Iglesias Martínez
/////////////////////////
Programa a ejecutar con GOOGLE COLAB.
************************************
Google Colab es un sistema de inteligencia artificial creado por Google. Se trata de un sistema que permite, aparte de otras cosas, el funcionamiento como IDE de forma que puedes interactuar en un entorno de programación Python, y su ejecución y prueba en linea.
Para poder utilizarlo, deberás darte de alta, con una referencia de correo en gmail.
Es indudable su potencia en los entornos de Inteligencia artificial. Tiene grandes prestaciones gráficas al utilizar los módulos TensorFlow -de google-y la biblioteca escrita en Python -en código abierto- llamada Keras, capaz de ejecutarse sobre TensorFlow.
**********************************************************************************
La red de ejmplo que planteamos aquí, es un sistema neuronal en modo Sequential, que indica que es un tipo de modelo de redes neuronales artificiales en el cual las capas se apilan de manera secuencial, una encima de la otra. Es el enfoque más básico y comúnmente utilizado en el aprendizaje profundo (deep learning) con la biblioteca de Python llamada Keras.
La creación de un modelo Sequential en Keras sigue los siguientes pasos generales:
con la siguiente linea de código.
from tensorflow.keras.models import Sequential
En Keras, el modo Sequential permite construir modelos de redes neuronales de forma secuencial, donde cada capa se agrega secuencialmente una tras otra. Cada capa se conecta a la siguiente en el flujo de información, pasando la salida de una capa como entrada a la siguiente.
***************************************************************************************************
El programa que pongo a continuación está realizado en en Python3, en un entorno Linux, Ubuntu 20.04.6 LTS. Se supone que por defecto ya tienes instalada esta versión de python.
----------------------------------------------------------------------------------
Deberás tener cargado el ejecutor de carga pip. La forma de instalarlo es la siguiente:
sudo apt update
sudo apt install python3-pip
----------------------------------------------------------------------------------
Una vez que lo tengas instalado ya podrás instalar también los modulos necesarios para Google Colab, de la siguiente forma:
pip install tensorflow
pip install keras
Dado que en el encabezado del programa nos encontramos estos módulos:
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
También deberemos comprobar que están cargados.
*************************************************************************
BASICAMENTE ESTA ES LA EXPLICACIÓN DEL PROGRAMA.
****************************************************
Este programa utiliza TensorFlow y Keras para crear y entrenar un modelo de red neuronal que predice la conversión de temperatura de Celsius a Fahrenheit. Aquí tienes una explicación paso a paso del programa:
Importa las bibliotecas necesarias:
numpy para manejar matrices y operaciones numéricas.
matplotlib.pyplot para visualizar los resultados.
Sequential de keras.models para crear un modelo de red neuronal secuencial.
Dense de keras.layers para agregar capas densamente conectadas a la red.
Crea los datos de entrada:
Define dos arrays de NumPy: Celsius y Fahrenheit, que contienen los pares de valores de temperatura para el entrenamiento del modelo.
Crea la red neuronal:
Inicializa un modelo secuencial llamado model.
Agrega tres capas densamente conectadas a la red:
La primera capa tiene 20 neuronas, utiliza la función de activación ReLU y espera un solo valor de entrada (input_dim=1).
La segunda capa tiene 10 neuronas y también utiliza la función de activación ReLU.
La tercera capa tiene una sola neurona y utiliza la función de activación lineal.
Compila el modelo:
Utiliza el optimizador Adam y la función de pérdida de error cuadrático medio (mean_squared_error).
Entrena el modelo:
Utiliza el método fit para entrenar el modelo con los datos de entrada Celsius y Fahrenheit.
Se especifican 20,000 rondas o vueltas de de entrenamiento -- con este dato se puede jugar empezando por valores más pequeños y viendo como va aumentando el aprendizaje-- y se establece verbose=0 para no mostrar la salida de entrenamiento durante el proceso.
Evalúa el modelo:
Utiliza el método evaluate para calcular la pérdida del modelo en los datos de entrada Celsius y Fahrenheit.
Imprime la pérdida del modelo.
Visualiza los resultados:
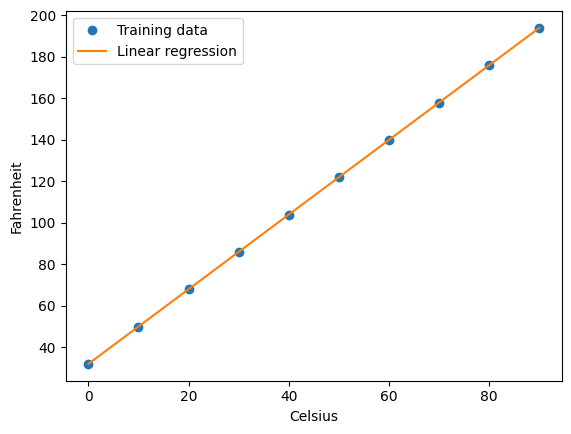
Grafica los datos de entrenamiento (Celsius y Fahrenheit) como puntos ('o').
Grafica las predicciones del modelo utilizando model.predict(Celsius) y una línea ('-').
Agrega etiquetas de los ejes y una leyenda para identificar los datos de entrenamiento y las predicciones del modelo.
Realiza una predicción:
Utiliza el modelo entrenado para predecir la temperatura en Fahrenheit para un valor de Celsius de 80.
Imprime la predicción resultante.
En resumen, este programa entrena un modelo de red neuronal para predecir la conversión de temperatura de Celsius a Fahrenheit y muestra los resultados a través de una visualización gráfica.
****************************************************************************
Si quieres puedes experimentar con el programa.
Busca en google -google Colab-
Informate del mismo, estudialo un poco, quizás lo encuentres apasionante.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
EXPLICACIÓN PORMENORIZADA DE LAS LINEAS DE CÓDIGO
***********************************************************************************************************
"""
Importamos los módulos necesarios.
---------------------------------
import numpy as np ** Este Modulo permite trabajar con Arrays
import matplotlib.pyplot as plt **Este módulo permite trabajar con graficos
from keras.models import Sequential **Nos permite trabajar con redes secuenciales.
from keras.layers import Dense **"Dense" es un término utilizado para
referirse a una capa densamente conectada
o completamente conectada en una red neuronal.
"""
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
"""
Creamos la entrada de datos por medio de los arrays.
Les llamamos a las entradas Celsius y ahrenheit.
"""
Celsius = np.array([0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
Fahrenheit = np.array([32, 50, 68, 86, 104, 122, 140, 158, 176, 194])
"""
Creamos la red neural.
---------------------
El modelo será de tipo secuencial, llamando a esa función.
en el módulo keras.models.
Dense(20): Esto indica que queremos agregar una capa densa con 20 neuronas.
Cada neurona en esta capa estará conectada a todas las
neuronas de la capa anterior y de la capa siguiente.
input_dim=1: Este argumento especifica la dimensión de la entrada a la capa.
En este caso, se indica que la capa recibirá una entrada unidimensional.
Esto significa que se espera una entrada de un solo valor.
activation='relu': Aquí se especifica la función de activación
que se utilizará en cada neurona de la capa. En este caso, se utiliza
la función de activación "ReLU" (Rectified Linear Unit).
La función ReLU es una función no lineal que se utiliza
comúnmente en redes neuronales y es conocida
por su capacidad para introducir no linearidad en el modelo.
*****************************************************************
ReLU(x) = max(0, x)
La función de activación ReLU (Rectified Linear Unit)
es una función no lineal ampliamente utilizada en
redes neuronales. La función ReLU se define de la siguiente manera:
para cualquier valor de entrada x, la función ReLU
devuelve 0 si x es negativo y x mismo si x es no negativo.
La función ReLU es popular en el campo del aprendizaje
profundo debido a sus propiedades deseables.
Algunas de las razones por las que se utiliza la función ReLU son:
No linealidad: La función ReLU introduce no linealidad
en la red neuronal, lo que permite que el modelo aprenda
relaciones no lineales entre las características de entrada.
Esto es esencial para capturar patrones complejos en los datos.
Eficiencia computacional: La función ReLU es computacionalmente
eficiente de calcular en comparación con funciones más complejas,
como la función sigmoide o la tangente hiperbólica.
Esto puede ser beneficioso, especialmente en redes neuronales profundas con muchas capas.
Evita el desvanecimiento del gradiente: En el entrenamiento de redes neuronales,
el desvanecimiento del gradiente puede ser un problema cuando las
derivadas de las funciones de activación son muy pequeñas.
La función ReLU evita este problema ya que tiene una derivada constante de 1 para x > 0, lo
que permite que los gradientes fluyan sin decaer rápidamente.
Sin embargo, una limitación de la función ReLU es que
no es diferenciable en x = 0.
Esto puede hacer que el entrenamiento sea más difícil
en algunos casos, especialmente cuando se utilizan
técnicas de optimización basadas en gradientes.
Para abordar este problema, se pueden utilizar variantes
suaves de la función ReLU, como la función Leaky ReLU o la función ReLU paramétrica,
que permiten cierto flujo de gradiente incluso para valores negativos de x.
****************************************************************
model.add(Dense(1, activation='linear'))
En una red neuronal, la función de activación 'linear'
(lineal) significa que no se aplica ninguna función de activación no lineal a
la salida de una capa específica.
Cuando se utiliza una función de activación lineal,
la salida de una neurona o capa simplemente se
calcula como una combinación lineal de las
entradas sin ninguna transformación no lineal
aplicada. Esto significa que la salida es
proporcionalmente igual a la suma ponderada de las entradas.
"""
model = Sequential()
model.add(Dense(20, input_dim=1, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='linear'))
# Compilación del modelo
"""
En la compilación de un modelo de red neuronal, se especifican tres aspectos clave:
Función de pérdida (loss function): La función de pérdida define cómo se calcula
la discrepancia entre las salidas predichas por el modelo y las salidas reales o
etiquetas del conjunto de datos. El objetivo del entrenamiento es minimizar
esta función de pérdida. La elección de la función de pérdida depende del
tipo de problema que se esté abordando, como regresión,
clasificación binaria o clasificación multiclase.
Optimizador: El optimizador determina cómo se ajustan
los pesos y los sesgos de la red neuronal durante el
entrenamiento para minimizar la función de pérdida.
El optimizador utiliza algoritmos como el descenso de
gradiente estocástico (SGD) o algoritmos más avanzados
como Adam o RMSprop. Cada optimizador tiene sus propias
configuraciones y parámetros adicionales que se pueden
ajustar según sea necesario.
Métricas:
Las métricas se utilizan para evaluar el
rendimiento del modelo durante el entrenamiento
y la evaluación. Estas métricas proporcionan
información adicional sobre la precisión,
el error o cualquier otra medida relevante.
Algunas métricas comunes incluyen la precisión (accuracy)
para problemas de clasificación y el error cuadrático
medio (mean squared error) para problemas de regresión.
Después de configurar estos aspectos,
el modelo está listo para ser entrenado utilizando
los datos de entrenamiento proporcionados. Durante el
entrenamiento, el modelo utilizará la función de
pérdida y el optimizador para ajustar los pesos y
los sesgos de las capas de la red neuronal con el
objetivo de minimizar la pérdida y mejorar el
rendimiento en función de las métricas establecidas.
"""
model.compile(optimizer='adam', loss='mean_squared_error')
#Entrenamiento del modelo
"""[
El "entrenamiento del modelo" en una red neuronal se refiere
al proceso de ajustar los pesos y los sesgos de la red neuronal
utilizando un conjunto de datos de entrenamiento con el objetivo
de aprender patrones y relaciones en
los datos. Durante el entrenamiento, el modelo se expone
repetidamente a los ejemplos de entrenamiento,
calcula las salidas correspondientes y actualiza los parámetros
internos en función de la diferencia entre las salidas predichas y las salidas reales.
El entrenamiento de un modelo de red neuronal implica los siguientes pasos generales:
Inicialización de pesos: Los pesos y los sesgos de la red neuronal
se inicializan de forma aleatoria o mediante algún enfoque
específico, como la inicialización de Xavier o He.
Paso hacia adelante (Forward pass): Los datos de entrenamiento se propagan
a través de la red neuronal en una dirección, desde la capa de entrada
hasta la capa de salida. Las salidas se calculan mediante una
combinación lineal de los pesos y los sesgos, seguidos de
la aplicación de funciones de activación no lineales en cada capa.
Cálculo de la función de pérdida: Se compara la salida predicha
por el modelo con la salida real correspondiente del conjunto de
datos de entrenamiento utilizando una función de pérdida.
La función de pérdida mide qué tan bien se está desempeñando
el modelo en la tarea específica y proporciona una medida de
la discrepancia entre las salidas predichas y las salidas reales.
Retropropagación (Backpropagation):
El algoritmo de retropropagación se utiliza para calcular
las contribuciones relativas de cada peso y sesgo en la
función de pérdida. Se propaga el gradiente del error
hacia atrás a través de la red neuronal,
calculando las derivadas parciales de la función de
pérdida con respecto a cada peso y sesgo.
Estas derivadas se utilizan para actualizar
los pesos y sesgos mediante un proceso llamado optimización.
Optimización de los parámetros: Los pesos
y sesgos se actualizan utilizando un algoritmo
de optimización, como el descenso de gradiente
estocástico (SGD), Adam o RMSprop.
Estos algoritmos ajustan los parámetros de la
red neuronal en la dirección que reduce
la función de pérdida, utilizando la información
del gradiente calculada durante la retropropagación.
Repetición: Los pasos 2-5 se repiten para varios
ejemplos de entrenamiento hasta que se alcance un
criterio de detención, como un número máximo de iteraciones
(épocas) o una mejora aceptable en el rendimiento del modelo.
El proceso de entrenamiento busca encontrar
los valores óptimos para los pesos y sesgos de la
red neuronal que minimicen la función de pérdida, y
permitan que el modelo haga predicciones precisas en
datos no vistos. Una vez que el modelo está entrenado,
se puede utilizar para hacer predicciones en nuevos
ejemplos o para realizar otras tareas relacionadas con la inferencia.
"""
model.fit(Celsius, Fahrenheit, epochs=20000, verbose=0)
# Evaluación de el modelo
loss = model.evaluate(Celsius, Fahrenheit)
print('Loss:', loss)
# TRAZAR RESULTADOS.
"""
"Trazar los resultados" en una red neuronal se refiere a visualizar
o representar gráficamente los resultados obtenidos durante el entrenamiento o
la evaluación del modelo. La visualización de los resultados puede proporcionar
información importante sobre el rendimiento y el comportamiento del modelo,
así como ayudar a identificar posibles problemas o mejoras.
Aquí hay algunos tipos comunes de trazado de resultados en una red neuronal:
Gráficas de pérdida (Loss plots): Se representan gráficamente las curvas
de pérdida a lo largo de las épocas durante el entrenamiento. Esto muestra
cómo disminuye la pérdida a medida que el modelo se entrena y proporciona
información sobre la convergencia y la estabilidad del modelo.
Gráficas de métricas de rendimiento: Si se han definido métricas
de rendimiento adicionales, como la precisión o el error, se
pueden trazar para evaluar el rendimiento del modelo durante
el entrenamiento o la evaluación. Esto ayuda a comprender
cómo el rendimiento del modelo evoluciona a medida que se realiza el entrenamiento.
Visualización de predicciones: Se pueden trazar las predicciones
del modelo junto con las etiquetas reales para un conjunto de
datos de evaluación o pruebas. Esto permite comparar
visualmente las predicciones del modelo con los valores
reales y evaluar qué tan cerca están.
Mapas de calor (Heatmaps): En el caso de problemas de clasificación,
especialmente en clasificación de imágenes, se pueden utilizar mapas
de calor para visualizar las regiones de la imagen que el modelo
considera más importantes para tomar una decisión de clasificación.
Estos mapas de calor resaltan las áreas de la imagen que
tienen un mayor impacto en las predicciones del modelo.
Representaciones de características (Feature representations):
En redes neuronales convolucionales, se pueden trazar las
representaciones aprendidas en diferentes capas de la red
para visualizar cómo las características se transforman a
medida que se profundiza en la red. Esto puede ayudar a
entender qué tipo de características o patrones la red
está aprendiendo a reconocer.
La visualización de los resultados en una red
neuronal puede proporcionar una comprensión más
profunda del rendimiento del modelo y ayudar en el
análisis y la mejora del mismo. Además, los gráficos y
visualizaciones pueden ser útiles para comunicar los
resultados a otras personas de manera más intuitiva.
"""
plt.plot(Celsius, Fahrenheit, 'o')
plt.plot(Celsius, model.predict(Celsius), '-')
plt.xlabel('Celsius')
plt.ylabel('Fahrenheit')
plt.legend(['Training data', 'Linear regression'], loc='best')
plt.show()
celsius_value = 100
fahrenheit_prediction = model.predict(np.array([80]))
print('Prediccion para Hilario:', fahrenheit_prediction[0])
#Fórmula habitual de cálculo por un algoritmo con esta formula
#(80 °C × 9 / 5) + 32 = 176 °F
Comentarios sobre la versión: V-1. (0)
No hay comentarios