"""
----------------------------------------------
Tempus fugit
***********
Hilario Iglesias Martínez
*********************************************
webprogra_2.py
***********************************************
Plataforma Linux.
Ubuntu 20.04.6 LTS.
Editado y ejecutado en GOOGLE-COLAB.
**********************************************
Inventamos una función cualquiera de aplicación
para el ejenmplo:
f(x)=(π*x)/(x**2)+1
Se calculan para 18 Valores_Entrada, los Valores_Salida
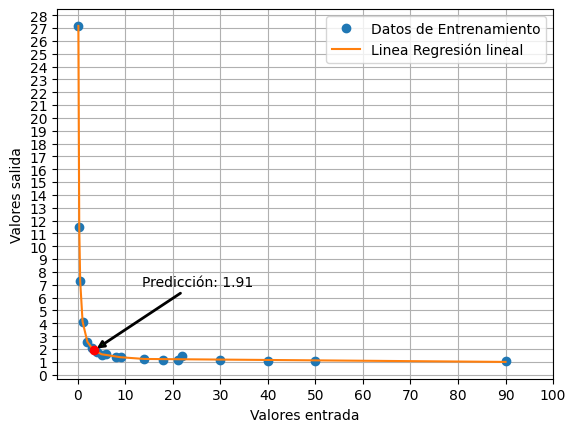
Si por ejemplo le pedimos una predicción
para un valor de 3,5 el resultado es el siguiente:
f(x)=(3,14151618*3,5)/(3,5**2)+1=1,89757605
Como vemos la predicción realizada por el programa es:
Prediccion de Salida: [1.91488977].
Existe una diferencia de:0,0173272
***************************************************
Neuronas de entrada:1
Primera capa de neuronas intermedia oculta:20
Segunda capa de neuronas intermedia oculta:10
Capa de salida:1
Con epochs=28000
En mi portatil ya viejo, tardó 6 mn 48 sg-
"""
"""
Incorporamos los módulos necesarios.
import numpy as np:
Importa la biblioteca NumPy y la renombra como "np" para
facilitar su uso. NumPy es una biblioteca de Python que proporciona soporte
para matrices y operaciones matemáticas de alto nivel.
------------------------------------------------------
import matplotlib.pyplot as plt:
Importa el módulo "pyplot" de la biblioteca Matplotlib y lo renombra como "plt".
Matplotlib es una biblioteca de visualización de datos en Python, y "pyplot"
es una interfaz para crear gráficos y figuras.
--------------------------------------------------------------------
from keras.models import Sequential:
Importa la clase "Sequential" del módulo "models" de la biblioteca Keras.
Keras es una biblioteca de aprendizaje profundo (deep learning) de alto nivel
que se ejecuta sobre TensorFlow u otros frameworks de backend. La clase "Sequential" se utiliza
para construir modelos secuenciales, que son modelos de redes neuronales donde
las capas se apilan de manera secuencial una tras otra.
------------------------------------------------------------------
from keras.layers import Dense: Importa la clase "Dense" del módulo "layers"
de la biblioteca Keras. "Dense" es una capa de red neuronal completamente
conectada, donde cada neurona de una capa está conectada a
todas las neuronas de la capa anterior.
"""
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
"""
Según la función ideada f(x)=(π*x)/(x**2)+1, vamos opteniendo
para valores de entrada de de x, valores de salida. Con ellos
vamos construyendo los dos arrays, disponiendo por orden
los valoes.
"""
Valores_Entrada = np.array([0.12, 0.3, 0.5, 1, 2, 3, 4, 5, 6, 8, 9, 14,
18, 21, 22, 30, 40, 50,90])
Valores_Salida = np.array([27.166, 11.466, 7.28, 4.14, 2.57, 2.046,
1.785, 1.523, 1.628, 1.392, 1.348, 1.224,
1.174, 1.149, 1.427, 1.104, 1.0785, 1.0628,1.0349])
"""
model = Sequential()
Se crea una instancia de un modelo secuencial. Esto es el comienzo de la definición del modelo.
model.add(Dense(20, input_dim=1, activation='relu'))
Se agrega la primera capa oculta al modelo.
Esta es una capa "Dense" completamente conectada con 20 neuronas.
La función de activación utilizada en esta capa es la función "relu" (unidad lineal rectificada),
que es una función no lineal comúnmente utilizada en redes neuronales. La capa tiene una entrada
(input_dim) de tamaño 1, lo que significa que espera datos unidimensionales
(por ejemplo, una serie de tiempo unidimensional).
model.add(Dense(10, activation='relu'))
Se agrega otra capa oculta al modelo.
Esta es otra capa "Dense" completamente conectada, pero esta vez con 10 neuronas.
También utiliza la función de activación "relu".
No es necesario especificar el tamaño de entrada en esta capa, ya que el modelo
automáticamente toma el tamaño de salida de la capa anterior como entrada.
model.add(Dense(1, activation='linear')):
Se agrega la capa de salida al modelo.
Esta es otra capa "Dense" completamente conectada, pero ahora tiene solo 1 neurona.
La función de activación utilizada es "linear", que simplemente realiza una
transformación lineal en los valores de entrada sin aplicar una función de activación no lineal.
Esta capa es adecuada para problemas de regresión donde se quiere obtener una salida continua.
En resumen, el modelo definido consta de una capa de entrada
con una neurona, dos capas ocultas con 20 y 10 neuronas respectivamente,
y una capa de salida con una neurona. El modelo está configurado
para procesar datos unidimensionales y es apropiado para problemas de regresión.
Puedes compilar este modelo con una función de pérdida adecuada y
luego entrenarlo utilizando datos y objetivos específicos para tu problema.
********************************************************************************
"""
model = Sequential()
model.add(Dense(20, input_dim=1, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='linear'))
"""
model.compile(optimizer='adam', loss='mean_squared_error'):
Esta línea de código es una parte esencial en la configuración
de un modelo de red neuronal para el entrenamiento.
La función compile() se utiliza para configurar el proceso de entrenamiento del modelo.
Aquí se definen los siguientes elementos clave:
optimizer='adam':
El parámetro optimizer se refiere al algoritmo
de optimización utilizado para ajustar los pesos de la red neuronal
durante el entrenamiento. "Adam" es un optimizador popular y eficiente
que se basa en la combinación de las técnicas de "Adaptive Moment Estimation"
y "Root Mean Square Propagation".
Es una elección común para la mayoría de los problemas de aprendizaje
profundo debido a su buen rendimiento y facilidad de uso.
loss='mean_squared_error':
El parámetro loss se refiere a la función de pérdida
utilizada durante el entrenamiento para medir el error entre las predicciones
del modelo y los valores reales. "Mean Squared Error" (MSE),
o error cuadrático medio, es una función de pérdida comúnmente utilizada
para problemas de regresión. Calcula el promedio de los errores cuadráticos
entre las predicciones y los valores reales. El objetivo del entrenamiento
será minimizar esta función de pérdida para mejorar las predicciones del modelo.
model.fit(Valores_Entrada, Valores_Salida, epochs=8000, verbose=0):
Esta línea de código se utiliza para entrenar el modelo utilizando los datos
de entrada (Valores_Entrada) y los valores de salida (Valores_Salida).
La función fit() es el proceso en el que el modelo ajusta sus pesos y
parámetros para hacer coincidir las salidas predichas con los valores
de salida reales. Los argumentos clave son:
Valores_Entrada:
Aquí se proporcionan los datos de entrada que se utilizarán
para entrenar el modelo. Deben estar en un formato que el modelo pueda entender,
como un array de NumPy o un tensor de TensorFlow.
Valores_Salida:
Estos son los valores objetivos o las salidas esperadas
correspondientes a los datos de entrada. También deben estar en un formato adecuado para el modelo.
epochs=8000:
El parámetro epochs se refiere al número de veces que el modelo pasará por
todo el conjunto de datos durante el entrenamiento. En este caso, el modelo
realizará 8000 iteraciones completas a través del conjunto de datos.
verbose=0: El parámetro verbose controla el nivel de verbosidad durante el entrenamiento.
En este caso, verbose=0 significa que no se mostrará ninguna salida durante el proceso de entrenamiento.
Si se establece en 1, se mostrará una barra de progreso durante el entrenamiento, y si se establece en 2,
se mostrará una línea por época.
En resumen, estas dos líneas de código se utilizan para configurar y entrenar
un modelo de red neuronal con el optimizador 'adam' y la función de pérdida
'mean_squared_error' durante 8000 épocas utilizando los datos de entrada y salida proporcionados.
"""
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(Valores_Entrada, Valores_Salida, epochs=28000, verbose=0)
# Evaluación de el modelo
loss = model.evaluate(Valores_Entrada, Valores_Salida)
print('Loss:', loss)
plt.plot(Valores_Entrada, Valores_Salida, 'o')
plt.plot(Valores_Entrada, model.predict(Valores_Entrada), '-')
plt.xlabel('Valores entrada')plt.ylabel('Valores salida')plt.legend(['Datos de Entrenamiento', 'Linea Regresión lineal'], loc='best')
plt.xticks(range(0, 101, 5))
plt.yticks(np.arange(0, max(Valores_Salida) + 1, 2.8))
#******************************************
# Para la grafica declaramos el Punto de predicción
prediccion_x = 3.5
prediccion_y = model.predict(np.array([prediccion_x]))[0][0]
# Ahora representamos para distinguirlo el punto de predicción con un círculo rojo
plt.plot(prediccion_x, prediccion_y, 'ro', label='Predicción')
# Ponemos una flecha en diagonal que señala el punto de predicción.
plt.annotate(f'Predicción: {prediccion_y:.2f}', xy=(prediccion_x, prediccion_y), xytext=(prediccion_x + 10, prediccion_y + 5),
arrowprops=dict(facecolor='green', arrowstyle='-|>', lw=2), fontsize=10)
plt.xticks(np.arange(0, 101, 10))
plt.yticks(np.arange(0, max(Valores_Salida) + 1, 1))
plt.grid(True)
#*******************************************
plt.show()
Valores_Salida_prediccion = model.predict(np.array([3.5]))
print('Prediccion de Salida:', Valores_Salida_prediccion[0])