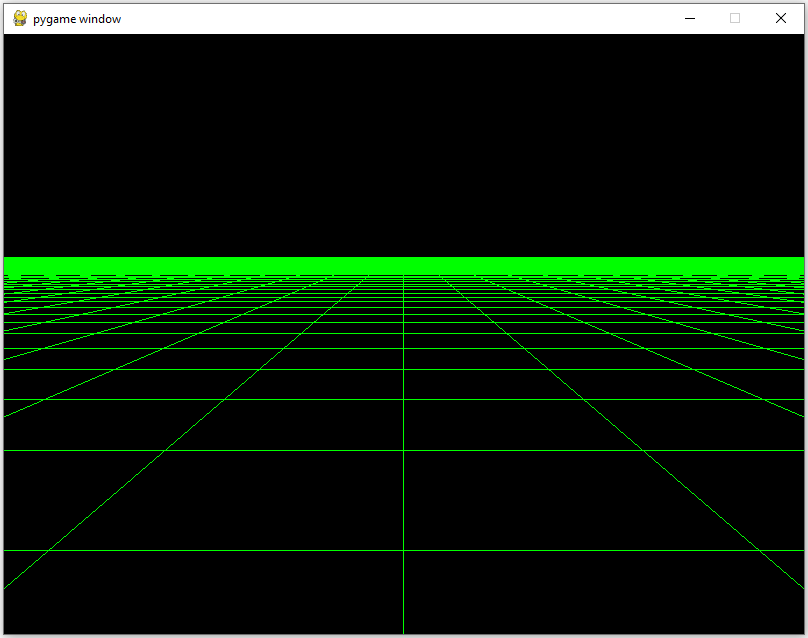
Este programa es un visor de modelos 3D en formato `.obj` que utiliza `OpenGL` y `pygame` para renderizar y manipular objetos 3D. Ofrece varias funciones de visualización como rotación, zoom, traslación, cambio entre vista en perspectiva y vista ortográfica, y otras acciones útiles para examinar el modelo cargado.
### Principales funciones del programa:
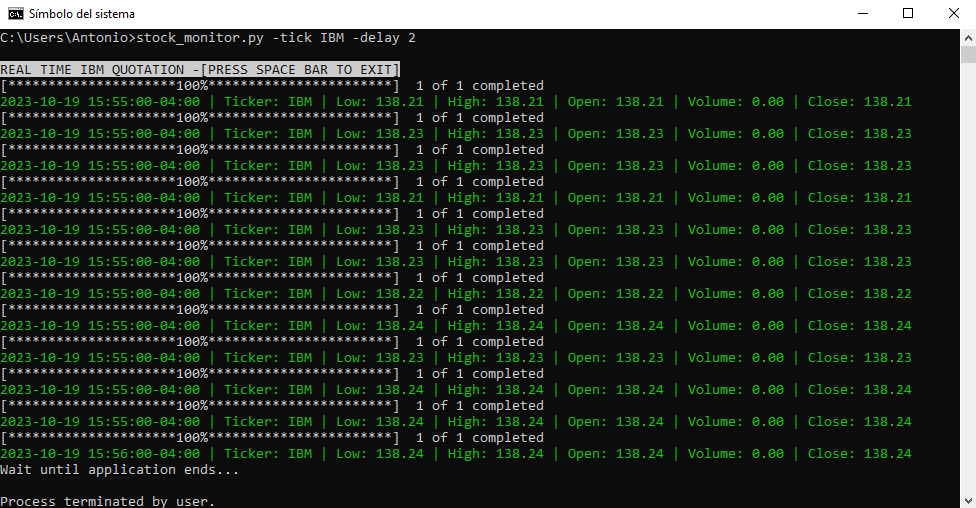
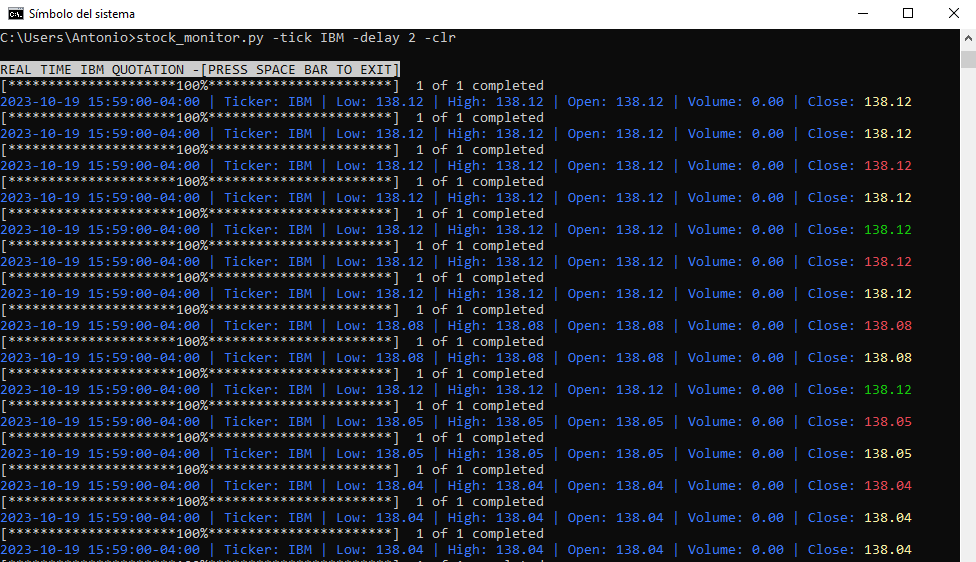
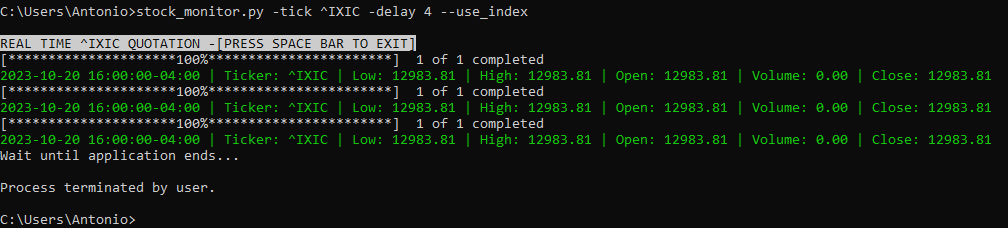
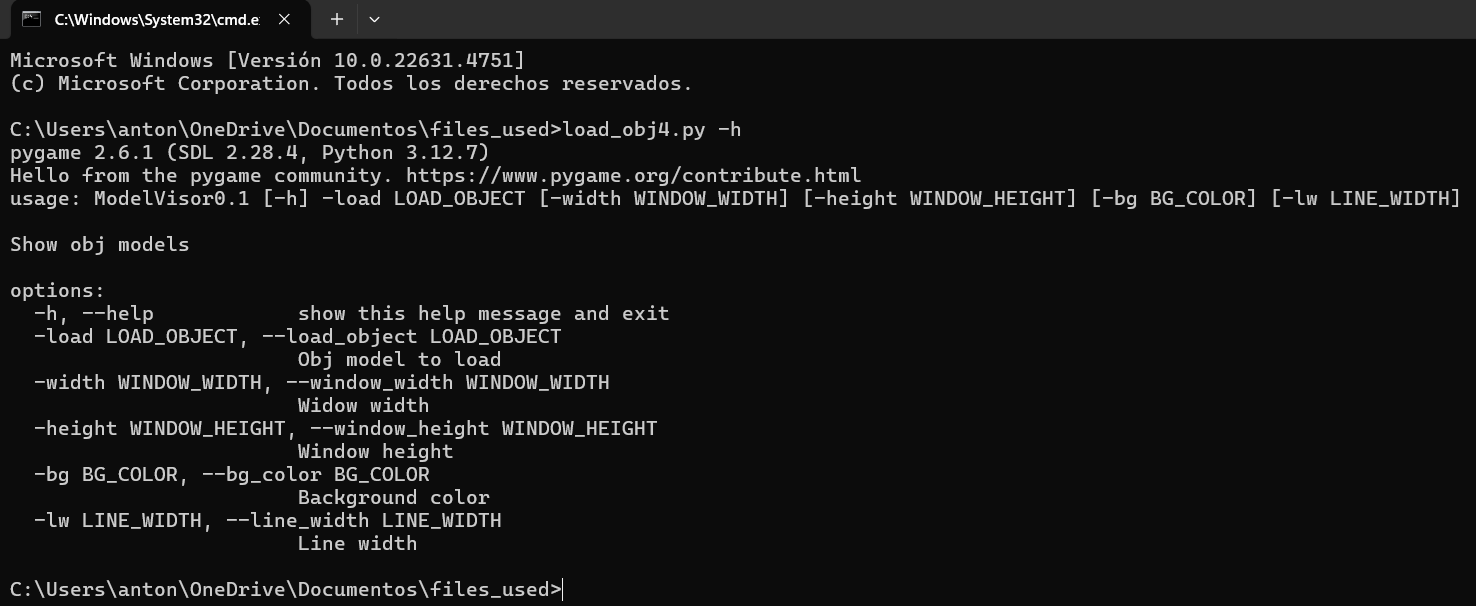
1. **Carga de modelo `.obj`:** El archivo `.obj` se especifica a través de un argumento y se carga mostrando los vértices, aristas y caras del modelo.
2. **Visualización en 3D:** Permite cambiar entre vista ortográfica y perspectiva.
3. **Rotación del modelo:** Utiliza cuaterniones para rotar el modelo sobre cualquier eje.
4. **Zoom y traslación:** Posibilidad de hacer zoom y mover el modelo en la pantalla.
5. **Información en pantalla:** Se puede mostrar/ocultar información como el nombre del modelo, escala, número de vértices, aristas y caras.
### Comandos principales:
- **Flechas del teclado:** Rotan el modelo en diferentes direcciones.
- **Tecla 'R':** Reinicia la rotación y escala del modelo.
- **Teclas 'M' y 'N':** Rotación en sentido horario y antihorario sobre el eje Z.
- **Tecla 'P':** Alterna entre vista en perspectiva y ortográfica.
- **Tecla 'X' y 'Z':** Zoom in y Zoom out, respectivamente.
- **Mouse:** Arrastrar con el clic izquierdo para mover la escena y usar la rueda del ratón para hacer zoom.
- **Tecla 'H':** Mostrar/ocultar la información en pantalla.
- **Tecla 'ESC':** Cierra el programa.
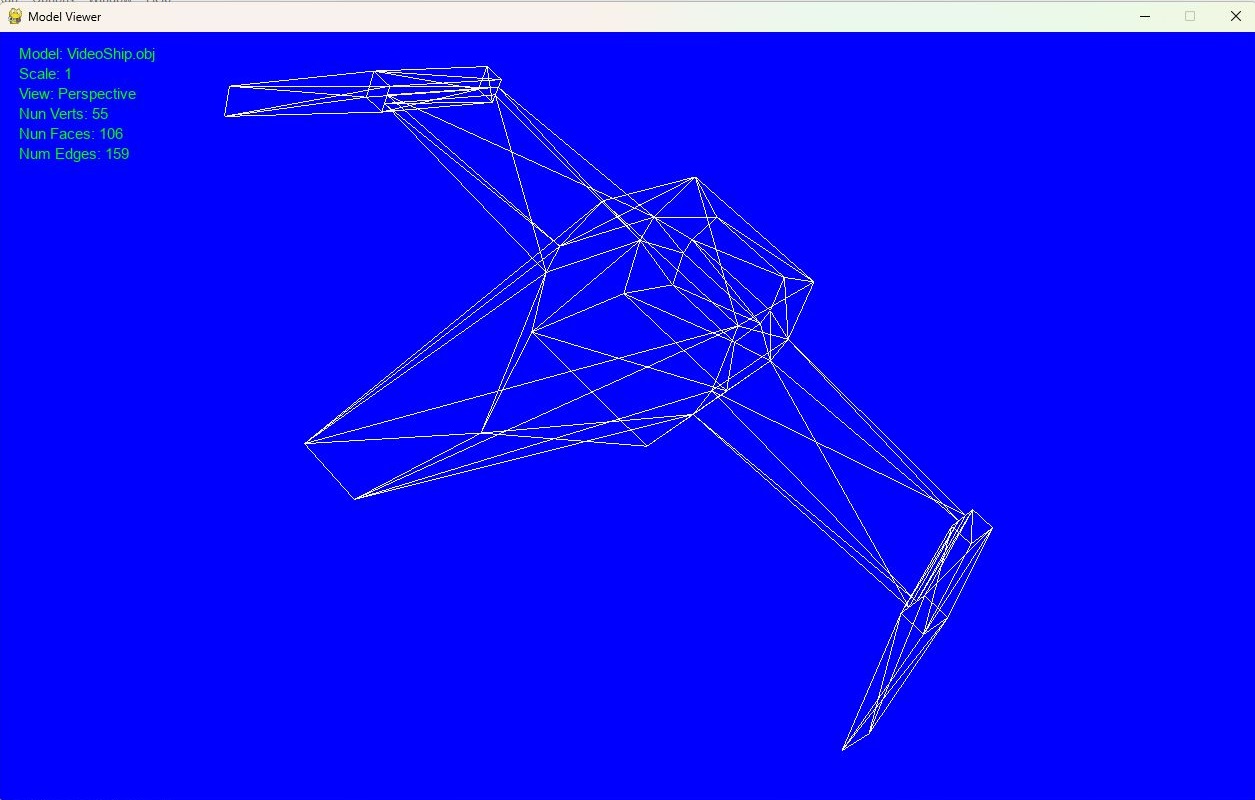
Para cualquier duda u observación, usen la sección de comentarios.

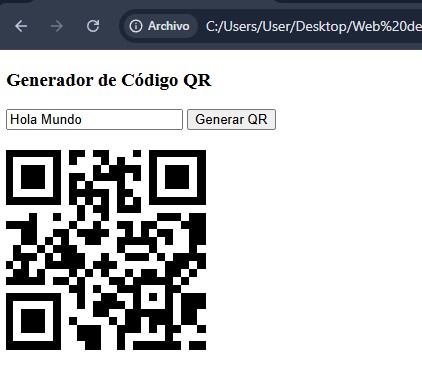
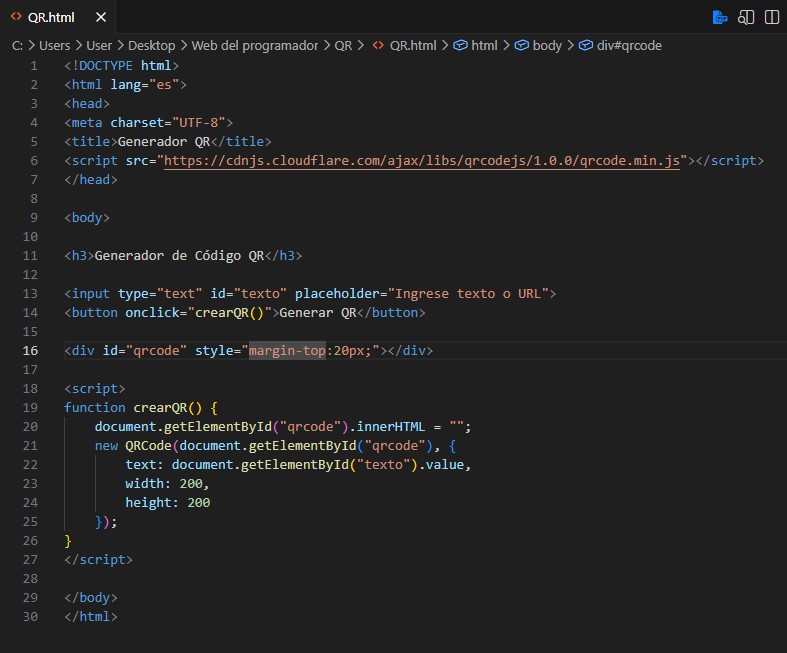
 Crear cuenta
Crear cuenta