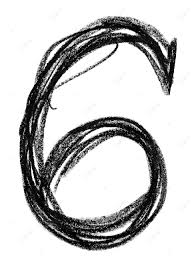
**********************************************************************************************************
Propongo este sencillo ejercicio llamado:
AULA-288_Transf_Apren_CNN.py, si utilizamos nuestro propio editor, Sublime text, y ejecutamos directamente en nuestra consola linux. O también llamado:
AULA-288_Transf_Apren_CNN.ipynb, si utlizamos para editar y ejecutar a
Google Colab.
En ambos casos, utilizamos indirectamente el método denominado
"Transferencia de aprendizaje", con el fin de apreciar cual es el proceso de este sistema de red Convolucional(CNN).
Se trata, utilizando
Machine Learning de la mano de TensorFlow y Keras, dos librerías Open Source que nos permiten adentrarnos en el Deep Learning de forma sencilla. De entre las muchas bibliotecas disponibles una de las más importantes es indiscutiblemente es TensorFlow, que se ha impuesto como la librería más popular en Deep Learning. Actualmente, sería difícil imaginar abordar un proyecto de aprendizaje sin ella.
Básicamente, para entenderlo, es una biblioteca de código abierto para realizar operaciones matemáticas de manera eficiente, especialmente diseñada para trabajar con redes neuronales y aprendizaje profundo (deep learning).
Keras, por otro lado, es una interfaz de alto nivel para construir y entrenar modelos de aprendizaje profundo. Facilita la construcción y experimentación con redes neuronales de una manera más simple y amigable.
TensorFlow.keras:
TensorFlow.keras es una implementación de la interfaz de Keras que está integrada directamente en TensorFlow. Esto significa que puedes usar las funciones y herramientas de TensorFlow mientras trabajas con la sencillez y flexibilidad de Keras.
En resumen, TensorFlow.keras es una combinación que aprovecha la potencia de TensorFlow para realizar cálculos eficientes en el fondo, mientras que proporciona una interfaz amigable y fácil de usar para diseñar y entrenar modelos de aprendizaje profundo mediante la simplicidad de Keras. Esto facilita el desarrollo de aplicaciones de inteligencia artificial y aprendizaje profundo de una manera más accesible para los desarrolladores.
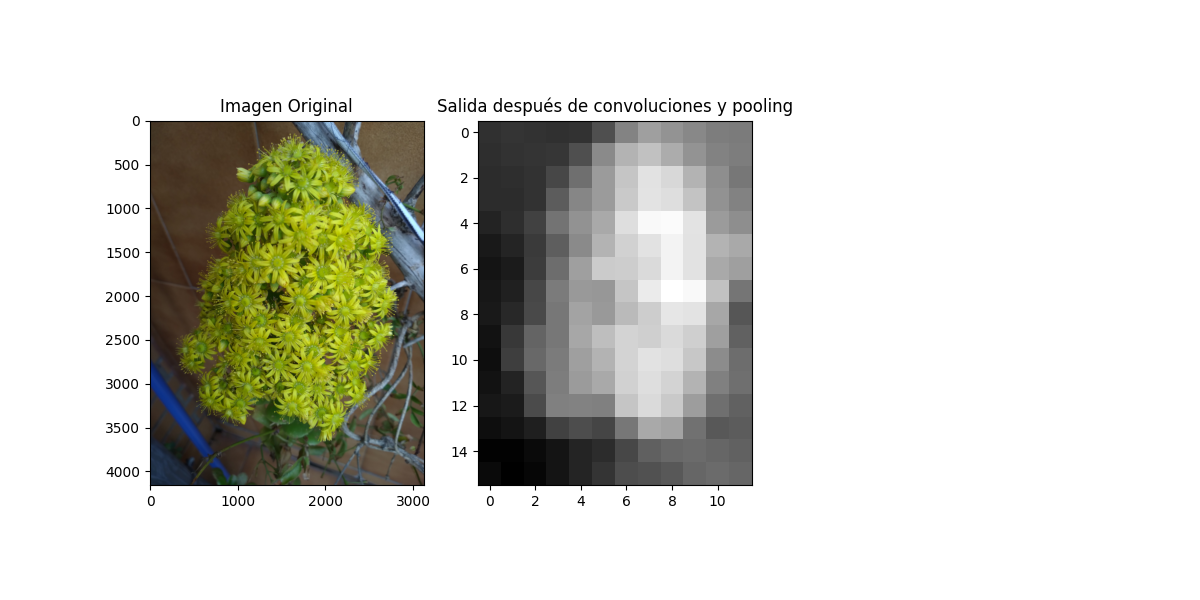
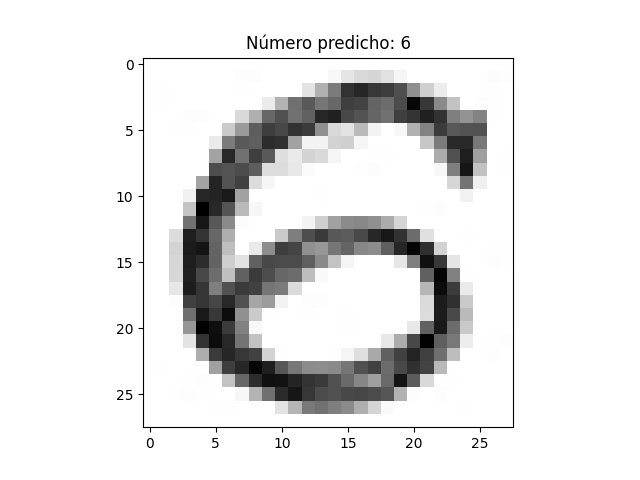
En este ejercicio, primero entrenamos el modelo, creando el mismo, alojandolo en el fichero: mnist_model.h5. En un caso, dependiendo el método de ejecución será guardado en Drive, o en nuestro propio ordenador. Luego cargaremos la imagen del número propuesto, que hemos fotografiado con el móvil, una vez dibujado a mano en color negro, sobre fondo blanco.
AQUÍ RESUMIMOS LOS PASOS NECESARIOS.
----------------------------------
Dibujar el número:
Preparar el papel o la superficie: Asegúrate de tener un fondo claro y limpio para que el número se destaque.
Dibuja el número: Utiliza un lápiz o bolígrafo para dibujar claramente el número en el papel. Trata de mantener el trazo claro y definido.
Contraste: Asegúrate de que haya suficiente contraste entre el número y el fondo para que el modelo pueda distinguirlo fácilmente.
Fotografiar el número:
Buena iluminación: Coloca la hoja con el número en un lugar bien iluminado. La iluminación uniforme puede ayudar a obtener una imagen de mejor calidad.
Ángulo y enfoque: Fotografía el número desde arriba para evitar distorsiones. Asegúrate de que la imagen esté enfocada y que el número sea claramente visible.
Fondo simple: Trata de tener un fondo simple y sin distracciones para que el modelo se centre en el número.
Preprocesamiento de la imagen:
Recortar y redimensionar: Recorta la imagen para que solo contenga el número y redimensiona la imagen según sea necesario.
Convertir a escala de grises: Convierte la imagen a escala de grises si es un número en blanco y negro, o a escala de colores si es en color.
Utilizar el número en un modelo de CNN:
Preparar los datos: Dependiendo del modelo y la biblioteca que estés utilizando (por ejemplo, TensorFlow y Keras), es posible que necesites ajustar el formato de la imagen o realizar otras transformaciones.
Entrenar el modelo: Entrena tu modelo de CNN utilizando el conjunto de datos que has creado con las imágenes de los números.
Prueba el modelo: Utiliza nuevas imágenes para probar la capacidad de tu modelo para reconocer los números.
Recuerda que la calidad de las imágenes y la cantidad de datos de entrenamiento son factores críticos para el éxito de tu modelo de CNN. Cuanto más variados y representativos sean los datos de entrenamiento, mejor será la capacidad del modelo para generalizar y reconocer números en situaciones diversas.
COMO EJECUTAR EL EJERCICIO.
---------------------------
Como hemos comentado al inicio, podemos utilizar dos métodos.
1-GOOGLE COLAB.
--------------
En este caso tendremos una cuenta abierta en Google Colab, y en Drive, con el fin de ejecutar online el ejercicio. Montando debidamente Drive.
Deberemos especificar correctamente las rutas tando de la carga de la imagen del número a predecir, como la descarga y alojamiento del fichero.
2-BAJO CONSOLA LINUX.
-------------------
En mi caso el ejercicio se utiliza
Ubuntu 20.04.6 LTS, y el editor Sublime Text.
En este caso, también deberemos especificar correctamente las rutas tando de la carga de la imagen del número a predecir, como la descarga y alojamiento del fichero.
*************************************************************
Con el fin de que no haya conflictos con
CUDA, hemos colocado esta linea de código en ambos ejercicios:
Para utilizar la CPU de tu ordenador, aunque en el caso de Google Colab, utilizamos su sistema online.
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # Establece la variable de entorno para usar la CPU de tu ordenador, al no tener, en muchos casos una tarjeta NVIDEA.
---------------------------------------------------------
QUE ES CUDA:
CUDA es una plataforma de cómputo paralelo desarrollada por NVIDIA que permite utilizar la potencia de procesamiento de las unidades de procesamiento gráfico (GPU) para realizar cálculos de propósito general. La sigla CUDA proviene de "Compute Unified Device Architecture" (Arquitectura de Dispositivo Unificado para Cómputo, en español).
A continuación, te proporciono algunos puntos clave sobre CUDA:
Programación en paralelo: CUDA proporciona un entorno de programación en paralelo que permite a los desarrolladores aprovechar la capacidad de procesamiento masivo de las GPUs para realizar cálculos intensivos. Esto es especialmente útil para aplicaciones que pueden dividirse en tareas independientes que se pueden ejecutar simultáneamente.
Modelo de programación: CUDA utiliza un modelo de programación basado en el lenguaje de programación C, lo que facilita a los desarrolladores escribir código para ejecutar en las GPUs de NVIDIA.
Núcleos de procesamiento: Las GPUs de NVIDIA están compuestas por un gran número de núcleos de procesamiento, que pueden ejecutar tareas de forma paralela. CUDA permite a los desarrolladores escribir programas que distribuyen estas tareas en los núcleos de manera eficiente.
Aplicaciones comunes: CUDA se utiliza comúnmente en aplicaciones de alto rendimiento, como el procesamiento de imágenes y videos, simulaciones científicas, aprendizaje profundo (deep learning), criptografía y otros campos que requieren un procesamiento intensivo.
Bibliotecas y herramientas: NVIDIA proporciona bibliotecas y herramientas específicas de CUDA, como cuBLAS (para álgebra lineal básica), cuDNN (para redes neuronales profundas), y otras, que facilitan el desarrollo de aplicaciones de alto rendimiento.
Desarrollo de software: Para utilizar CUDA, los desarrolladores suelen escribir código en lenguaje CUDA C y utilizan herramientas proporcionadas por NVIDIA, como el compilador NVCC (NVIDIA CUDA Compiler).
En resumen, CUDA es una tecnología que permite aprovechar la potencia de las GPUs de NVIDIA para realizar cálculos paralelos, lo que resulta especialmente valioso en aplicaciones que requieren un alto rendimiento computacional.