Descenso de Gradiente Aula-28
Python
Publicado el 29 de Octubre del 2023 por Hilario (124 códigos)
361 visualizaciones desde el 29 de Octubre del 2023
[center]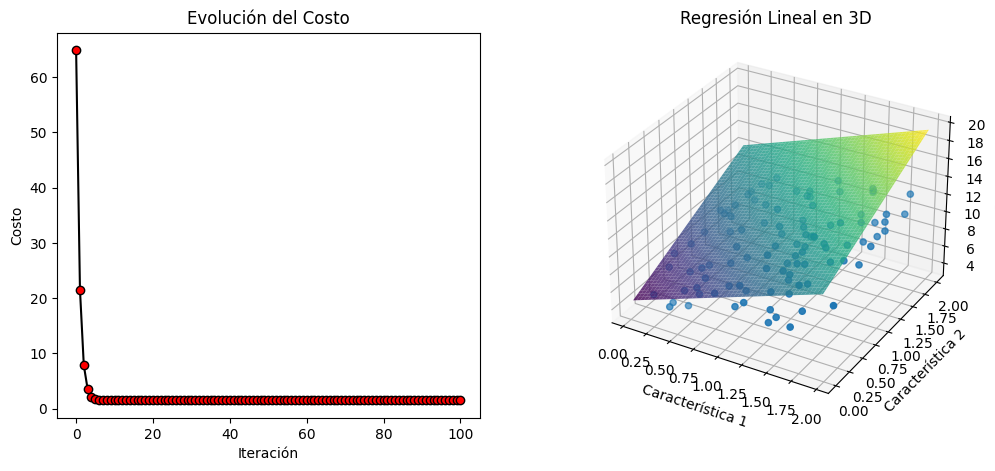
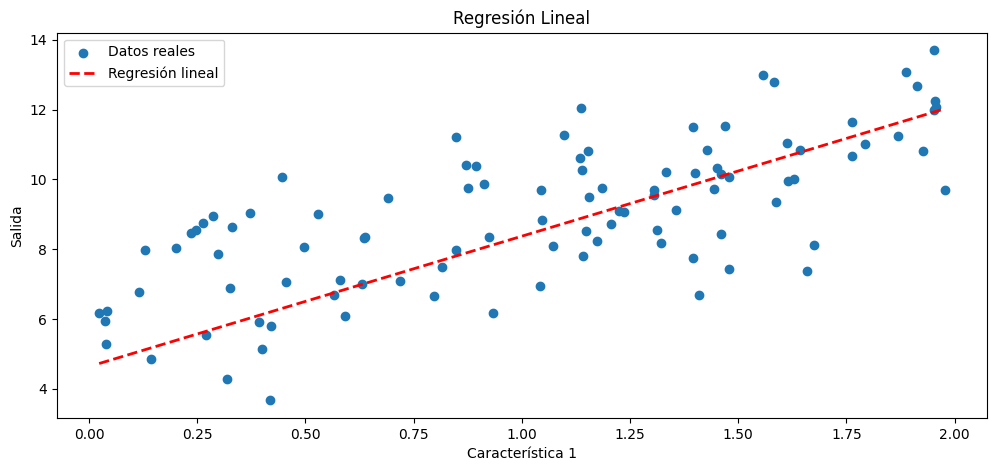
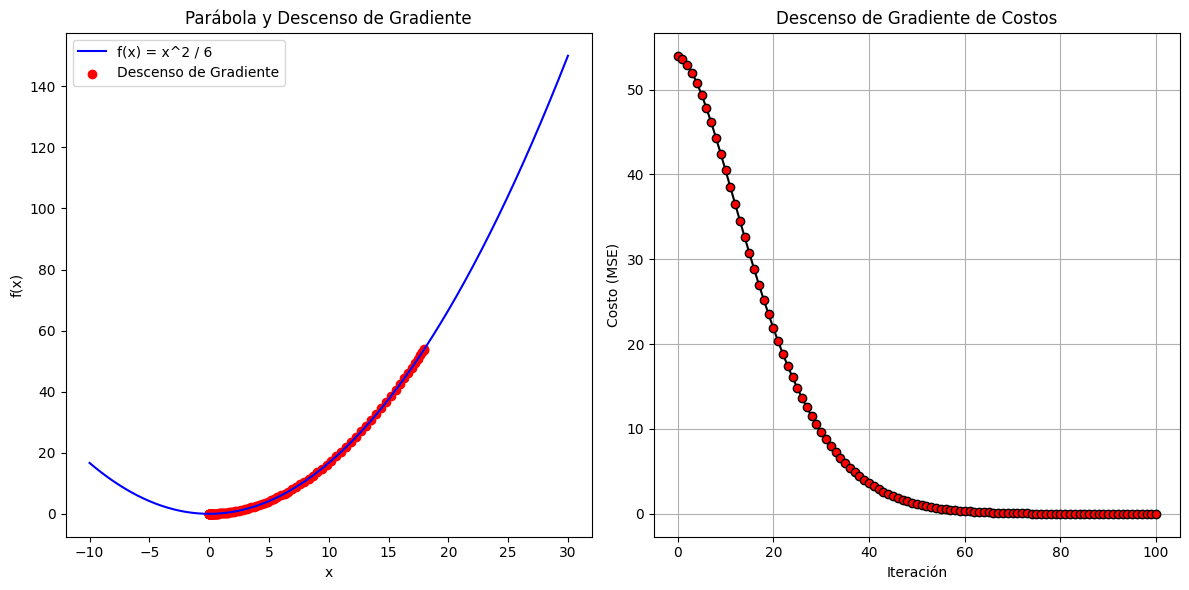
En este sencillo ejercicio:Descn_Mult_Momentun_Ejemp_Aula-28-Oct.py, tratamos de explicar como realizar un descenso de gradiente multiple, aplicando al mismo un momentum, para regular un descenso de gradiente , digamos, rápido de forma que el mismo no sea errático.
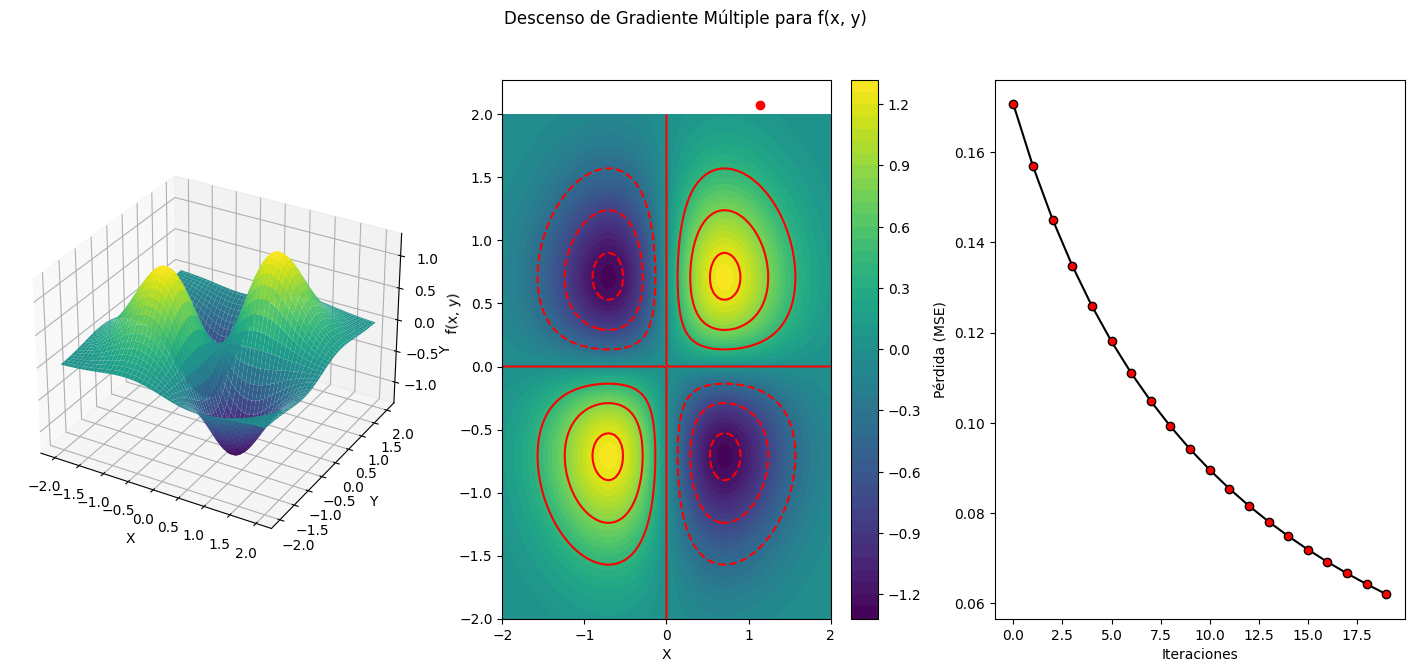
Una regresión múltiple es un tipo de análisis de regresión en el que se busca modelar la relación entre una variable de respuesta (dependiente) y múltiples variables predictoras (independientes o características). En otras palabras, en lugar de predecir una única variable de respuesta a partir de una única característica, se intenta predecir una variable de respuesta a partir de dos o más características. La regresión múltiple puede ser útil para comprender cómo varias características influyen en la variable de respuesta.
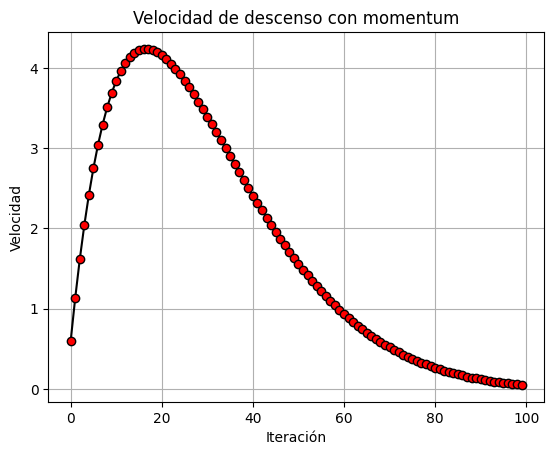
Cuando aplicas "momentum" a un algoritmo de regresión, normalmente estás utilizando una variante del descenso de gradiente llamada "descenso de gradiente con momentum." El momentum es una técnica que ayuda a acelerar la convergencia del algoritmo de descenso de gradiente, especialmente en problemas en los que el parámetro de costo es irregular, o tiene pendientes pronunciadas. En lugar de utilizar únicamente el gradiente instantáneo en cada iteración, el descenso de gradiente con momentum tiene en cuenta un promedio ponderado de los gradientes pasados, lo que le permite mantener una especie de "momentum" en la dirección de la convergencia.
A continuación, os proporcionaré un ejemplo de regresión múltiple con descenso de gradiente con momentum,y datos sintéticos en Python. En el mismo utilizamos, aparte de otras, la biblioteca NumPy para generar datos sintéticos, y aplicar el descenso de gradiente con momentum.
También se incluye en el ejercicio, una disposición de graficas, para hacerlo más didactico. El alunmno, podrá jugar, o experimentar con los parámetros iniciales e hiperparámetros, para seguir su evolución.
En resumen este es un ejercicio sencillo, que explicaremos en clase, paso a paso, para su comprensión. Como siempre utilizaremos en nuestros ordenadores la plataforma Linux, con Ubuntu 20. También realizaremos la práctica en Google Colab.
En este sencillo ejercicio:Descn_Mult_Momentun_Ejemp_Aula-28-Oct.py, tratamos de explicar como realizar un descenso de gradiente multiple, aplicando al mismo un momentum, para regular un descenso de gradiente , digamos, rápido de forma que el mismo no sea errático.
Una regresión múltiple es un tipo de análisis de regresión en el que se busca modelar la relación entre una variable de respuesta (dependiente) y múltiples variables predictoras (independientes o características). En otras palabras, en lugar de predecir una única variable de respuesta a partir de una única característica, se intenta predecir una variable de respuesta a partir de dos o más características. La regresión múltiple puede ser útil para comprender cómo varias características influyen en la variable de respuesta.
Cuando aplicas "momentum" a un algoritmo de regresión, normalmente estás utilizando una variante del descenso de gradiente llamada "descenso de gradiente con momentum." El momentum es una técnica que ayuda a acelerar la convergencia del algoritmo de descenso de gradiente, especialmente en problemas en los que el parámetro de costo es irregular, o tiene pendientes pronunciadas. En lugar de utilizar únicamente el gradiente instantáneo en cada iteración, el descenso de gradiente con momentum tiene en cuenta un promedio ponderado de los gradientes pasados, lo que le permite mantener una especie de "momentum" en la dirección de la convergencia.
A continuación, os proporcionaré un ejemplo de regresión múltiple con descenso de gradiente con momentum,y datos sintéticos en Python. En el mismo utilizamos, aparte de otras, la biblioteca NumPy para generar datos sintéticos, y aplicar el descenso de gradiente con momentum.
También se incluye en el ejercicio, una disposición de graficas, para hacerlo más didactico. El alunmno, podrá jugar, o experimentar con los parámetros iniciales e hiperparámetros, para seguir su evolución.
En resumen este es un ejercicio sencillo, que explicaremos en clase, paso a paso, para su comprensión. Como siempre utilizaremos en nuestros ordenadores la plataforma Linux, con Ubuntu 20. También realizaremos la práctica en Google Colab.