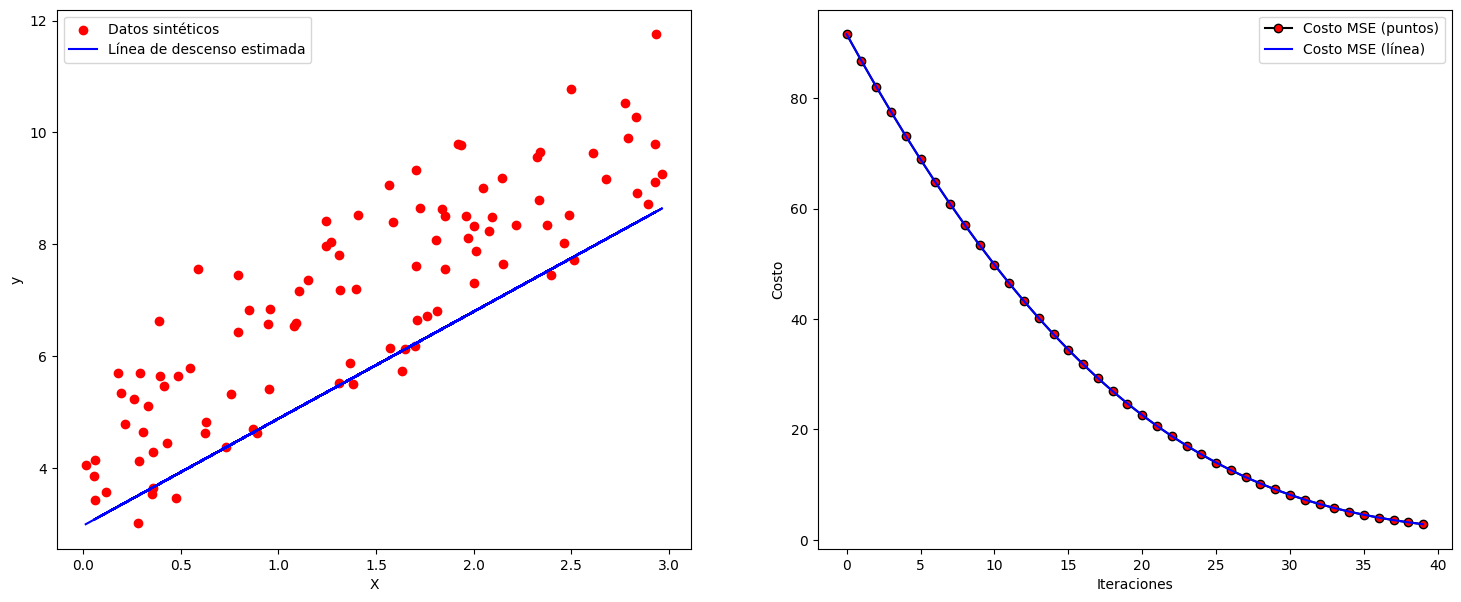
Descenso de gradiente tipo Adam.
Python
Publicado el 19 de Octubre del 2023 por Hilario (145 códigos)
813 visualizaciones desde el 19 de Octubre del 2023
Aquí hay una explicación simplificada de cómo funciona el algoritmo Adam:
Inicialización de parámetros: Se inician los parámetros del algoritmo, como la tasa de aprendizaje (learning rate), los momentos de primer y segundo orden, y se establece un contador de iteraciones.
Cálculo del gradiente: En cada iteración, se calcula el gradiente de la función de pérdida con respecto a los parámetros del modelo. Esto indica en qué dirección deben ajustarse los parámetros para reducir la pérdida.
Cálculo de momentos de primer y segundo orden: Adam mantiene dos momentos acumulativos, uno de primer orden (media móvil de los gradientes) y otro de segundo orden (media móvil de los gradientes al cuadrado).
Actualización de parámetros: Se utilizan los momentos calculados en el paso anterior para ajustar los parámetros del modelo. Esto incluye un término de corrección de sesgo para tener en cuenta el hecho de que los momentos se inicializan en cero. La tasa de aprendizaje también se aplica en esta etapa.
Iteración y repetición: Los pasos 2-4 se repiten durante un número especificado de iteraciones o hasta que se cumpla un criterio de parada, como la convergencia.
Adam se considera una elección popular para la optimización de modelos de aprendizaje profundo debido a su capacidad para adaptar la tasa de aprendizaje a medida que se entrena el modelo, lo que lo hace efectivo en una variedad de aplicaciones y evita problemas como la convergencia lenta o la divergencia en el entrenamiento de redes neuronales. Sin embargo, es importante ajustar adecuadamente los hiperparámetros de Adam, como la tasa de aprendizaje y los momentos, para obtener un rendimiento óptimo en un problema específico.