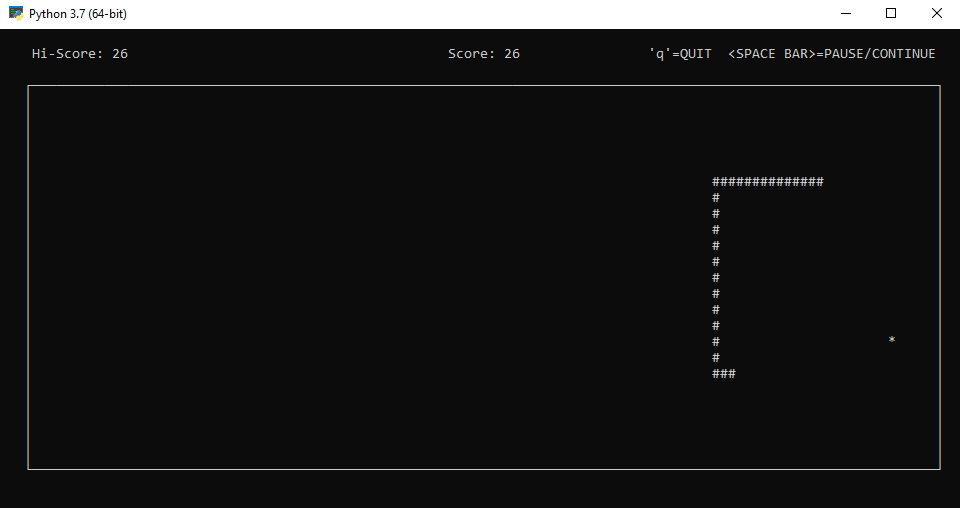
Juego de la Serpiente, en ASCII (versión con sonido)
Python
 (5)
(5)Actualizado el 13 de Mayo del 2024 por Antonio (76 códigos) (Publicado el 8 de Junio del 2020)
11.172 visualizaciones desde el 8 de Junio del 2020
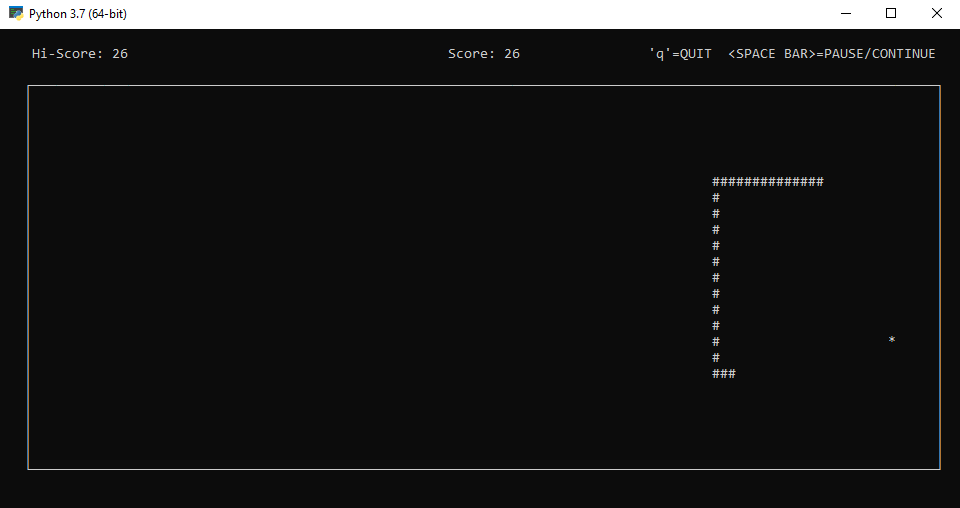
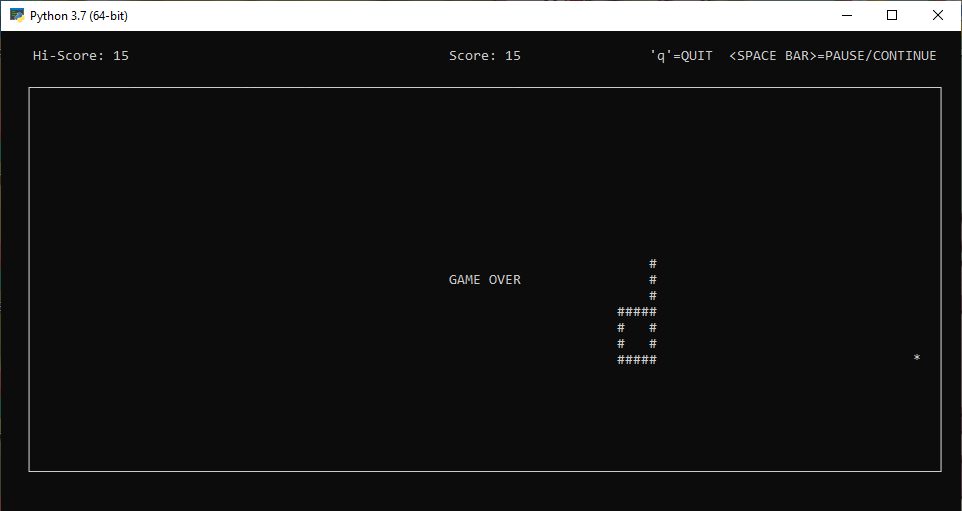
Nueva versión del Juego de la Serpiente, en la que se ha incluido sonido y 3 archivos de audio (incluidos en la carpeta). Para usar el programa adecuadamente, simplemente hay que descomprimir la carpeta en la que se encuentra.
BOTONES:
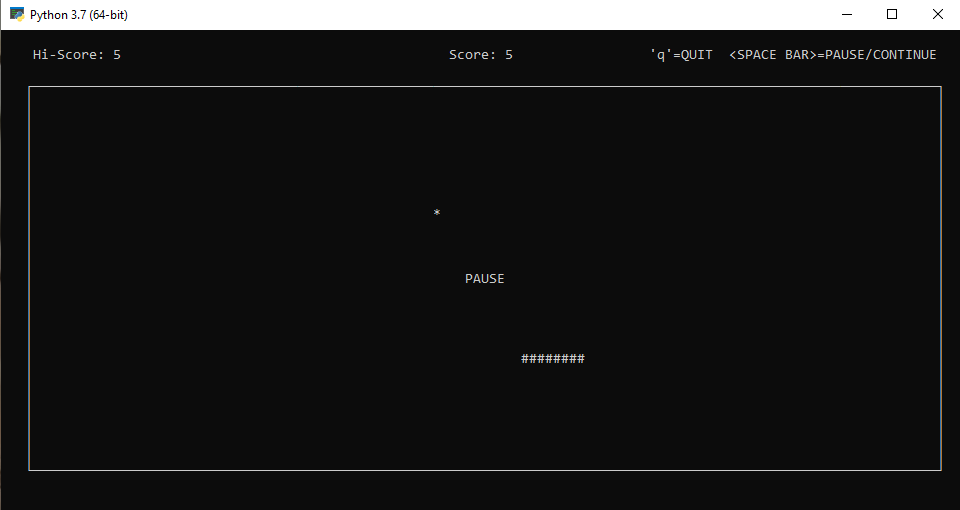
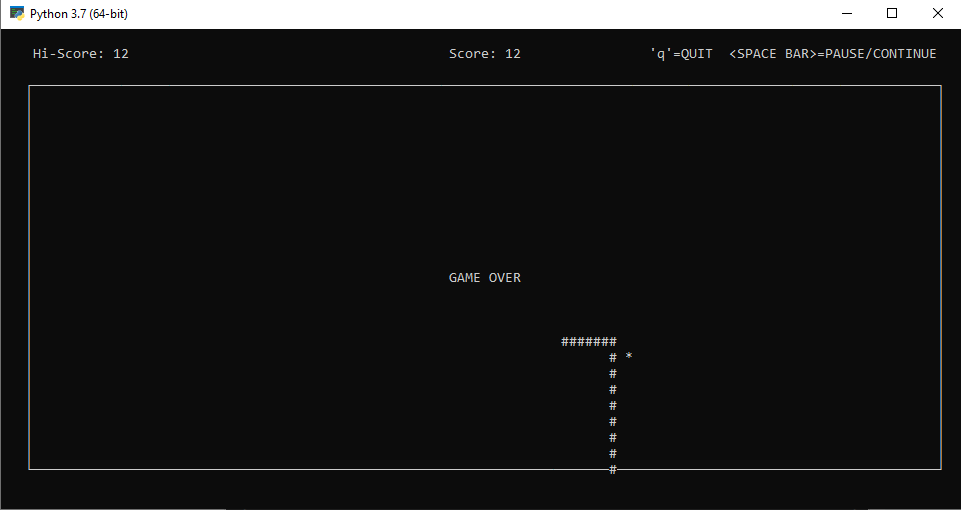
Mover serpiente: Botónes de dirección
Pause y reanudar partida pausada : Barra espaciadora.
Finalizar partida: tecla "q"
PARA CUALQUIER PROBLEMA, NO DUDEN EN COMUNICÁRMELO.
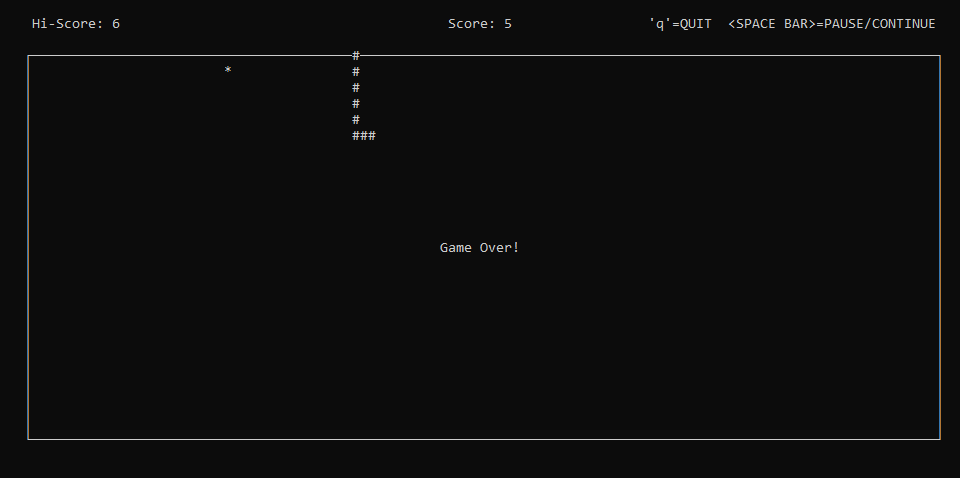
BOTONES:
Mover serpiente: Botónes de dirección
Pause y reanudar partida pausada : Barra espaciadora.
Finalizar partida: tecla "q"
PARA CUALQUIER PROBLEMA, NO DUDEN EN COMUNICÁRMELO.