Mostrando del 11 al 20 de 408 coincidencias
Se ha buscado por el tag: si
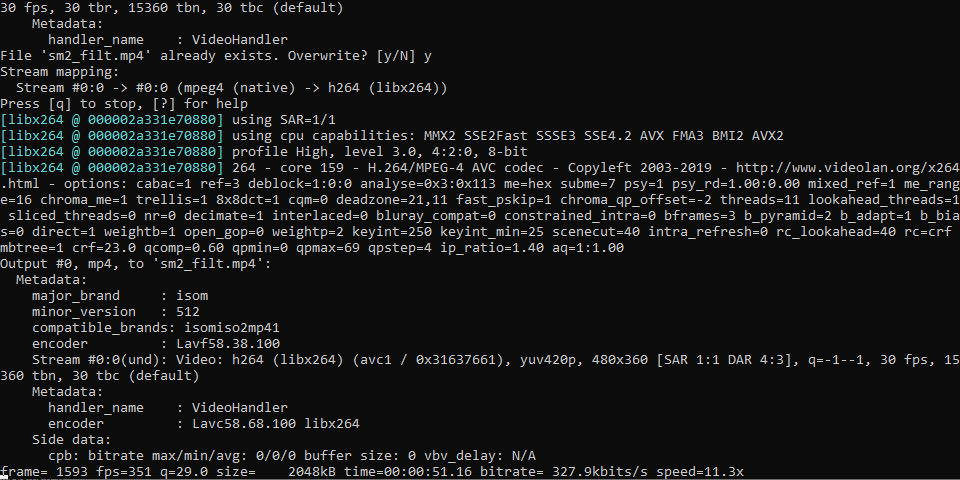
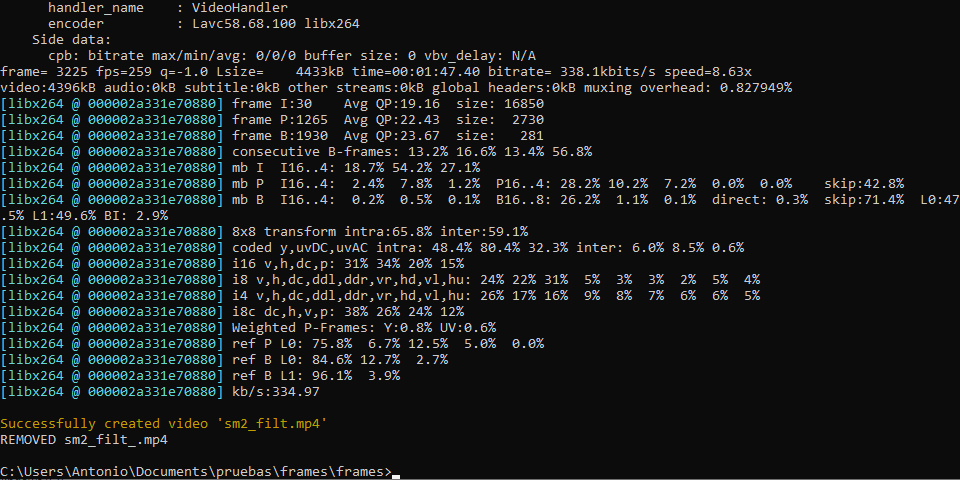
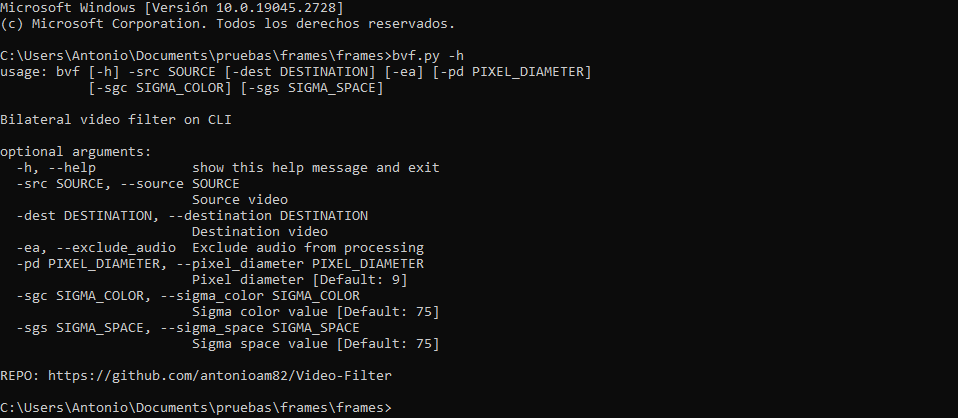
Programa para realizar filtrado de imagen en archivos de vídeo (preferiblemente de corta duración) utilizando el algoritmo de 'filtrado bilateral' pudiendo especificar los valores sigma de espacio y color y el diámetro del vecindario para cada pixel. Los vídeos filtrados se generan, por defecto, conservando su sonido, aunque se pueden generar sin este introduciendo el argumento '-ae'/'--exclude_audio'.
ARGUMENTOS:
-src/--source: Nombre del vídeo original (OBLIGATORIO)
-dest/--destination: Nombre del video a generar ('NewFilteredVid.mp4' por defecto)
-sgc/--sigma_color: Valor sigma para espacio de color (75 por defecto)
-sgs/--sigma_space: Valor sigma espacial (75 por defecto)
-pd/--pixel_diameter: Diámetro de la vecindad de píxeles (9 por defecto)
-ae/--exclude_audio: Excluir audio y generar video sin sonido (OPCIONAL)
PARA CUALQUIER DUDA U OBSERVACIÓN UTILIZEN LA SECCIÓN DE COMENTARIOS
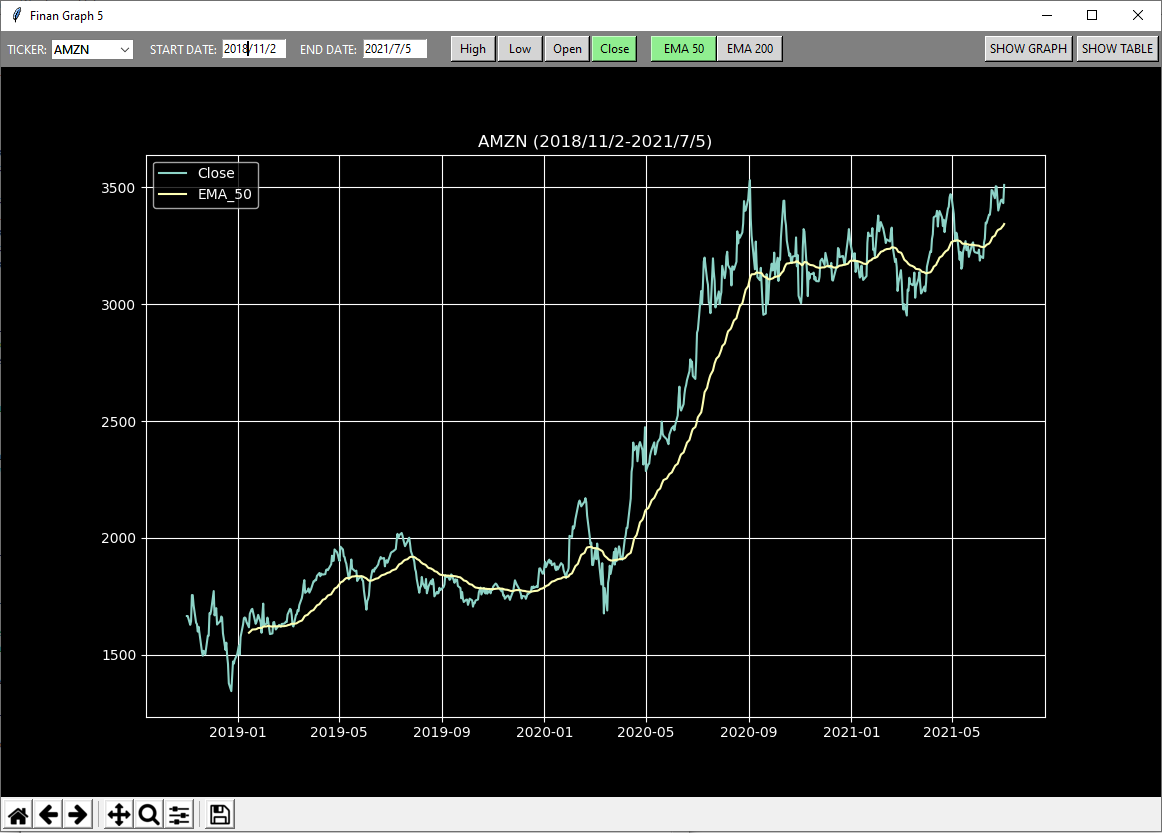
El programa muestra información relativa al precio máximo, mínimo, de apertura y cierre de un activo financiero (estos se irán almacenando en el archivo "symbols" que se generará al ejecutar el programa por primera vez) y para un periodo de tiempo. También muestra los gráficos relativos a las medias móviles exponenciales de 50 y 200 sesiones.
PARA CUALQUIER DUDA U OBSERVACIÓN USEN LA SECCIÓN DE COMENTARIOS.
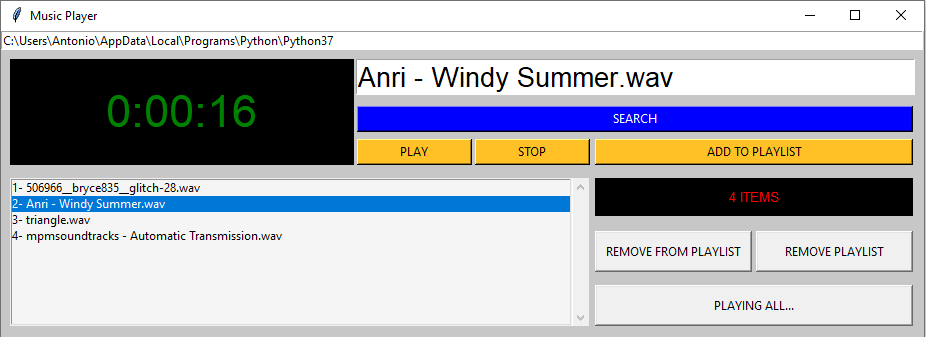
Programa para reproducir archivos de audio que incorpora la posibilidad de crear una lista de favoritos.
El programa necesita de un archivo "json" que se generará al ejecutarse por primera vez.
Esta versión incorpora la posibilidad de reproducir secuencialmente la lista de favoritos, para ello se usará el botón "PLAY ALL" (dicha reproducción se podrá finalizar igualmente con el botón "STOP").
PARA CUALQUIER DUDA U OBSERVACIÓN USEN LA SECCIÓN DE COMENTARIOS.
Les traigo un OCX simple, que les servirá para representar el típico estado On-Off.

Reacciona al hacer un
Click sobre el elemento, llamando al Evento
Change. Desde ahí capturan el valor (
TRUE ó
FALSE) y realizar la acción que quieran de acuerdo a éso.
Les adjunto el código fuente, junto al OCX compilado. Espero les sea de utilidad.
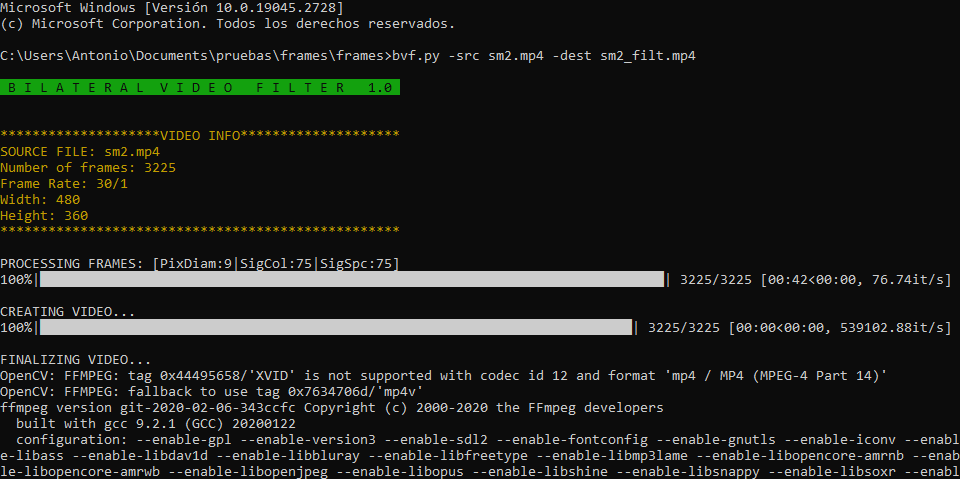
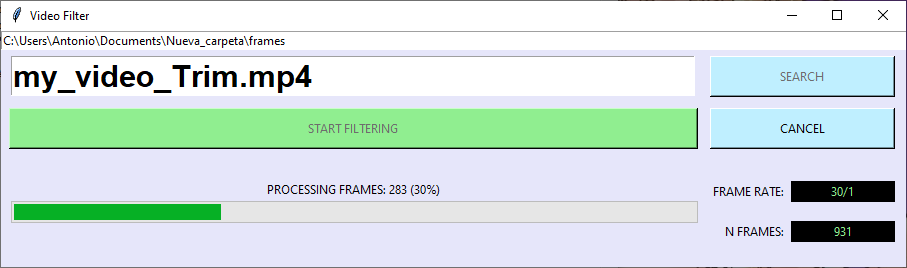
El presente programa se encarga de aplicar filtros sobre los fotogramas de un archivo de video empleando diferentes funciones. El programa realiza el filtrado frame a frame para a continuación generar un nuevo video con la secuencia de frames procesados (aplicando el frame rate del vídeo original). También usa el software "ffmpeg" para copiar el audio del vídeo original y añadirlo al vídeo resultante.
USO: Primeramente seleccionaremos el vídeo a filtrar mediante el botón "SEARCH". Una vez seleccionado iniciaremos el proceso con "START FILTERING" con el que empezaremos seleccionando la ubicación del nuevo vídeo, para a continuación iniciar el proceso (NOTA: La ruta del directorio de destino no deberá contener espacios en blanco). El proceso de filtrado podrá ser cancelado medinate el botón "CANCEL".
PARA CUALQUIER DUDA U OBSERVACIÓN USEN LA SECCIÓN DE COMENTARIOS.
El ejercicio, es el siguiente:
Ejercicio_Clas_Regre_Log-Aula-28.py
La clasificación de datos por regresión logística es una técnica de aprendizaje automático que se utiliza para predecir la pertenencia de un conjunto de datos a una o más clases. Aunque el nombre "regresión" logística incluye la palabra "regresión", este enfoque se utiliza para problemas de clasificación en lugar de regresión.
La regresión logística se emplea cuando se desea predecir la probabilidad de que una observación pertenezca a una categoría o clase específica, generalmente dentro de un conjunto discreto de clases. Por lo tanto, es una técnica de clasificación que se utiliza en problemas de clasificación binaria (dos clases) y clasificación multiclase (más de dos clases). Por ejemplo, se puede usar para predecir si un correo electrónico es spam (clase positiva) o no spam (clase negativa) o para clasificar imágenes en categorías como gatos, perros o pájaros.
La regresión logística utiliza una función logística (también conocida como sigmoide) para modelar la probabilidad de pertenecer a una clase particular en función de variables de entrada (características). La función sigmoide tiene la propiedad de que produce valores entre 0 y 1, lo que es adecuado para representar probabilidades. El modelo de regresión logística utiliza coeficientes (pesos) para ponderar las características y calcular la probabilidad de pertenencia a una clase.
Durante el entrenamiento, el modelo busca ajustar los coeficientes de manera que las probabilidades predichas se ajusten lo más cerca posible a las etiquetas reales de los datos de entrenamiento. Una vez que se ha entrenado el modelo, se puede utilizar para predecir la probabilidad de pertenencia a una clase para nuevos datos y tomar decisiones basadas en esas probabilidades, como establecer un umbral para la clasificación en una clase específica.
*************************************************************************************************************
Los pasos que realizamos en el ejercicio, son los siguientes:
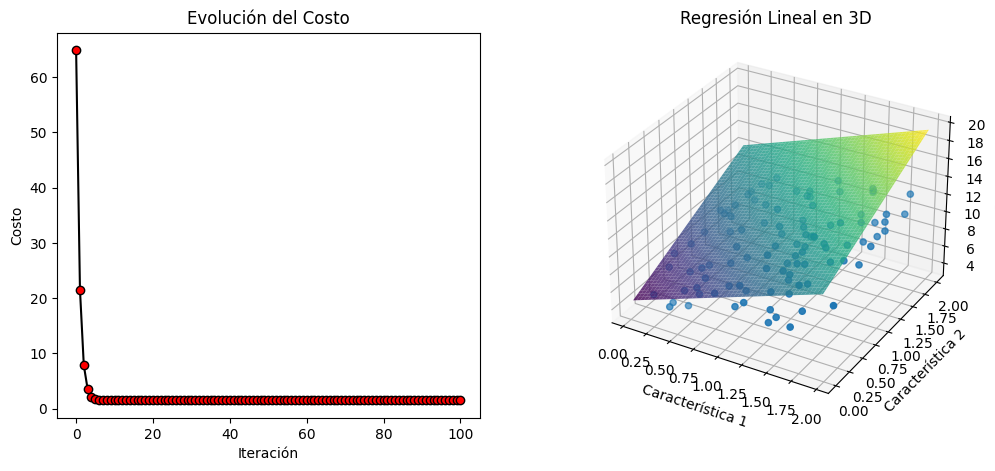
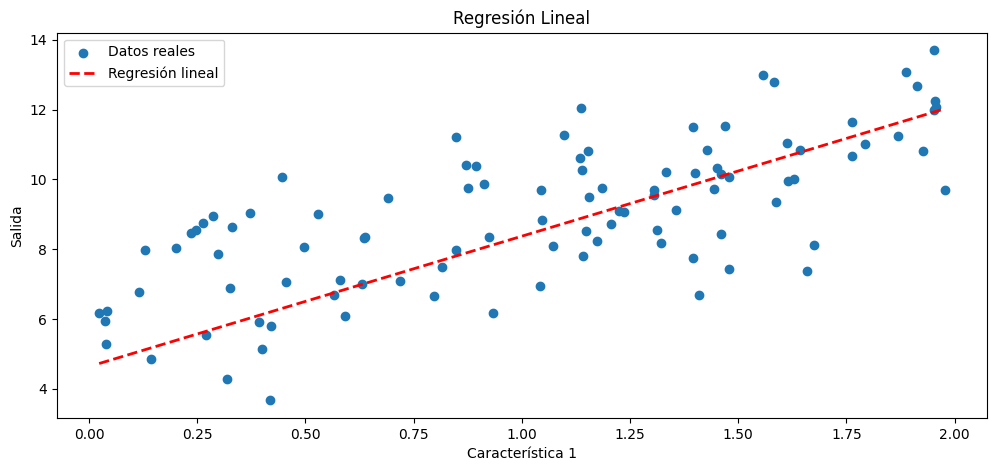
1-Generamos datos sintéticos donde la clase se determina por la suma de las dos características.
2-Implementamos la regresión logística desde cero sin el uso de scikit-learn, incluyendo el cálculo de 3-gradientes y la actualización de pesos.
4-Dibujamos los datos de entrada en un gráfico, junto con la línea de decisión que separa las clases.
En resumen, la regresión logística es una técnica de clasificación que modela las probabilidades de pertenencia a clases utilizando la función sigmoide y es ampliamente utilizada en una variedad de aplicaciones de aprendizaje automático.CuadernoAula-B-28-OCT-18.py
-----------------------------------------------------------------------------
La clasificación de datos mediante árboles de decisiones es un método de aprendizaje automático que se utiliza para categorizar o etiquetar datos en diferentes clases o categorías. Es una técnica de modelado predictivo que se basa en la creación de un "árbol" de decisiones, donde cada nodo interno del árbol representa una pregunta o una prueba sobre una característica específica de los datos, y las ramas que salen de ese nodo conducen a diferentes resultados o decisiones basadas en el valor de esa característica. Los nodos hoja del árbol representan las categorías o clases en las que se divide el conjunto de datos.
El proceso de clasificación a través de árboles de decisión implica:
Construcción del árbol: Se inicia con un nodo raíz que representa todo el conjunto de datos. Luego, se selecciona una característica y un umbral que se utilizará para dividir los datos en dos subconjuntos. Este proceso se repite recursivamente en cada subconjunto hasta que se alcanza un criterio de parada, como un tamaño máximo de profundidad del árbol, una cantidad mínima de muestras en los nodos hoja, o una impureza mínima.
Selección de características: En cada paso de división, se elige la característica que mejor separa los datos, lo que se logra al minimizar alguna métrica de impureza, como el índice de Gini o la entropía. La característica y el umbral que minimizan la impureza se utilizan para dividir los datos en dos ramas.
Predicción: Una vez construido el árbol, se utiliza para hacer predicciones sobre datos nuevos. Los datos nuevos se introducen en el árbol, siguiendo las ramas que corresponden a las características de esos datos, hasta llegar a un nodo hoja que representa la clase predicha.
Los árboles de decisión son atractivos porque son interpretables y fáciles de visualizar. Sin embargo, pueden ser propensos al sobreajuste (overfitting), especialmente si se construyen árboles muy profundos. Para abordar este problema, se pueden utilizar técnicas como la poda (pruning) o el uso de bosques aleatorios (random forests) que combinan múltiples árboles para mejorar la precisión y reducir el sobreajuste.
En resumen, la clasificación de datos mediante árboles de decisión es una técnica poderosa y ampliamente utilizada en aprendizaje automático para tareas de clasificación, donde el objetivo es predecir la categoría o clase a la que pertenecen los datos de entrada en función de sus características.
*********************************************************
Hilario Iglesias Martínez
**********************************************************
La función sigmoide es una función matemática que toma
cualquier número real como entrada y la transforma en
un valor en el rango de 0 a 1. Su forma característica
es una curva en forma de "S".
La función sigmoide es comúnmente utilizada en diversos campos,
como la biología, la psicología y el aprendizaje automático,
especialmente en las redes neuronales.
Forma:
f(x)=1 / (1 + e**(-x))
Derivada:
e**(-x) / (1 + e**(-x))**2
La función sigmoide toma valores positivos y negativos de
x y los mapea en el rango (0, 1), de modo que valores grandes de
x resultarán en valores cercanos a 1, y valores pequeños o negativos de
x resultarán en valores cercanos a 0.
Programa realizado bajo linux
Plataforma Ubuntu 20.04.6 LTS.
Editado con Sublime Text.
Ejecucion en consola linux.
python3 SigmoideWeb.py
Tambien se puede editar y ejecutar en Google Colab.