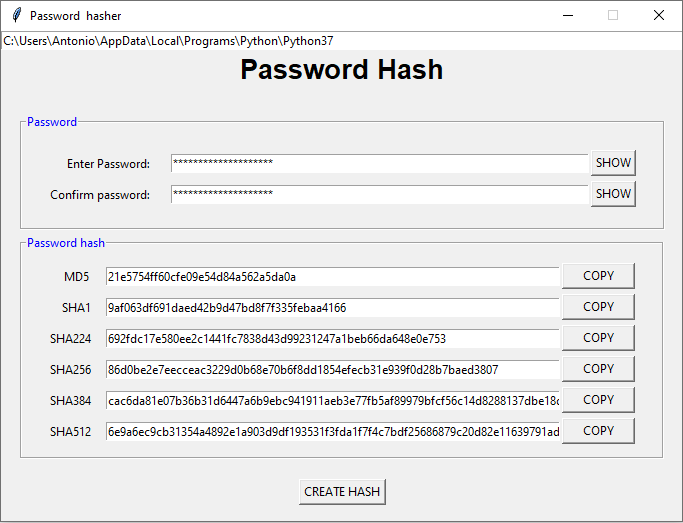
Generador de valores hash para contraseñas.
Python
Actualizado el 5 de Mayo del 2024 por Antonio (77 códigos) (Publicado el 20 de Noviembre del 2022)
2.318 visualizaciones desde el 20 de Noviembre del 2022
El siguiente programa genera valores hash para una contraseña, utilizando distintos algoritmos. También permite la copia de las salidas generadas.