Mostrar los tags: es
Mostrando del 11 al 20 de 730 coincidencias
Se ha buscado por el tag: es
python3 Ejercicio_Aula_23_Momentum.py
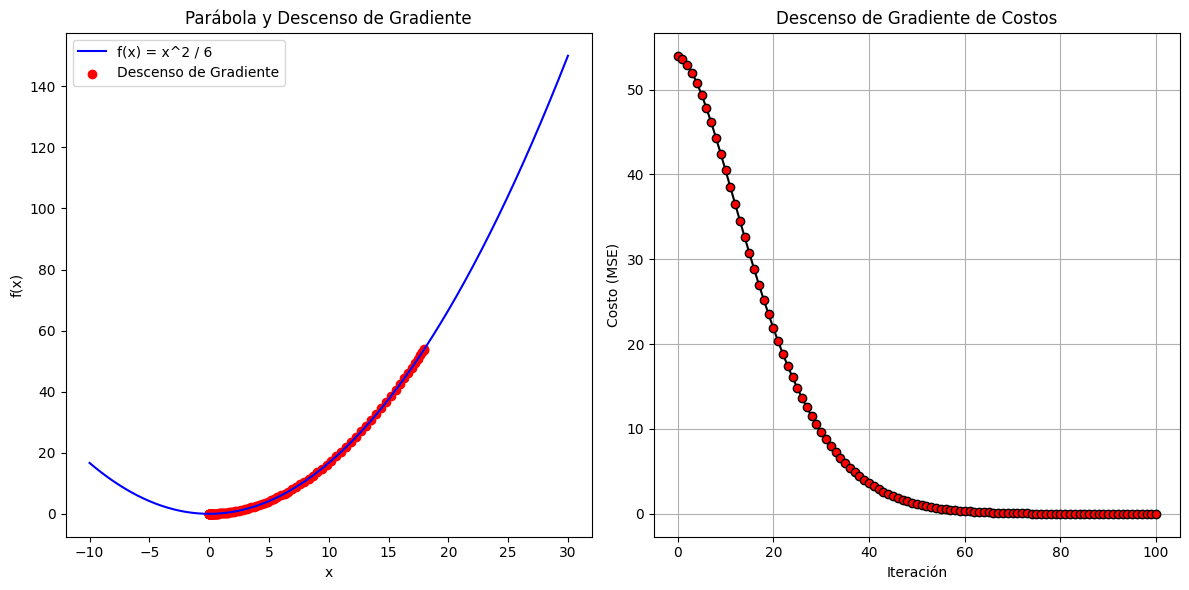
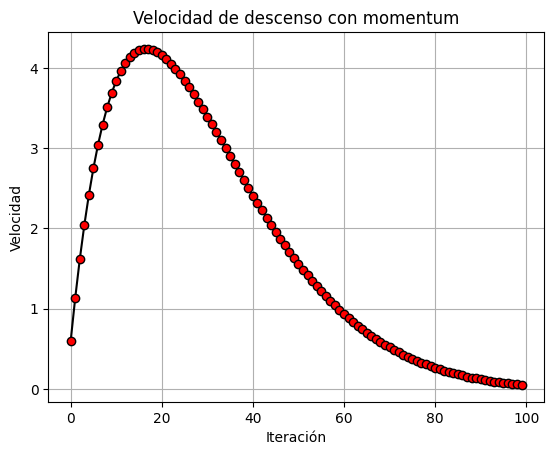
Sencillo ejercicio sobre un descenso de gradiente con momento, (Gradient Descent with Momentum en inglés).
Se trata de aplicar este algoritmo a una funcion parabolica del tipo: f(x) = x^2 / 6.
Cuya derivada es:x**2 / 6.
El descenso de gradiente con momento es una variante del algoritmo de descenso de gradiente utilizado en la optimización y entrenamiento de modelos de aprendizaje automático, particularmente en el contexto de redes neuronales y problemas de optimización no convexos. Su objetivo es acelerar la convergencia del descenso de gradiente y ayudar a evitar quedarse atrapado en óptimos locales.
La principal diferencia entre el descenso de gradiente con momento y el descenso de gradiente estándar es la adición de un término de "momentum" o impulso. En el descenso de gradiente estándar, en cada iteración, el gradiente actual se utiliza directamente para actualizar los parámetros del modelo. En cambio, en el descenso de gradiente con momento, se mantiene un promedio ponderado exponencial de los gradientes anteriores y se utiliza ese promedio para actualizar los parámetros.
El objetivo del término de momento es suavizar las actualizaciones de los parámetros y reducir las oscilaciones que pueden ocurrir cuando el gradiente varía significativamente en diferentes direcciones. Esto puede ayudar a acelerar la convergencia y a sortear barreras o mínimos locales en la función de costo
En este sencillo ejercicio que propongo, en vez de utilizar datos sintéticos de caráctear aleatorio de entrada, lo vamos a aplicar a una función parabólica.
El descenso de gradiente tipo Adam, o simplemente Adam (por Adaptive Moment Estimation), es un algoritmo de optimización utilizado en el campo del aprendizaje automático y la inteligencia artificial para ajustar los parámetros de un modelo de manera que se minimice una función de pérdida. Adam es una variante del descenso de gradiente estocástico (SGD) que combina técnicas de otros algoritmos de optimización para mejorar la convergencia y la eficiencia en la búsqueda de los mejores parámetros del modelo.
Aquí hay una explicación simplificada de cómo funciona el algoritmo Adam:
Inicialización de parámetros: Se inician los parámetros del algoritmo, como la tasa de aprendizaje (learning rate), los momentos de primer y segundo orden, y se establece un contador de iteraciones.
Cálculo del gradiente: En cada iteración, se calcula el gradiente de la función de pérdida con respecto a los parámetros del modelo. Esto indica en qué dirección deben ajustarse los parámetros para reducir la pérdida.
Cálculo de momentos de primer y segundo orden: Adam mantiene dos momentos acumulativos, uno de primer orden (media móvil de los gradientes) y otro de segundo orden (media móvil de los gradientes al cuadrado).
Actualización de parámetros: Se utilizan los momentos calculados en el paso anterior para ajustar los parámetros del modelo. Esto incluye un término de corrección de sesgo para tener en cuenta el hecho de que los momentos se inicializan en cero. La tasa de aprendizaje también se aplica en esta etapa.
Iteración y repetición: Los pasos 2-4 se repiten durante un número especificado de iteraciones o hasta que se cumpla un criterio de parada, como la convergencia.
Adam se considera una elección popular para la optimización de modelos de aprendizaje profundo debido a su capacidad para adaptar la tasa de aprendizaje a medida que se entrena el modelo, lo que lo hace efectivo en una variedad de aplicaciones y evita problemas como la convergencia lenta o la divergencia en el entrenamiento de redes neuronales. Sin embargo, es importante ajustar adecuadamente los hiperparámetros de Adam, como la tasa de aprendizaje y los momentos, para obtener un rendimiento óptimo en un problema específico.Sencillo ejemplo de un descenso de gradiente del tipo Nesterov.
Descen_Grad_Nesterov_Aula_B_28_18_OCT_github.py
----------------------------------------------------------------------------------------------------
El descenso de gradiente tipo Nesterov, también conocido como el "descenso de gradiente acelerado de Nesterov" o "NAG" por sus siglas en inglés (Nesterov Accelerated Gradient Descent), es una variante del algoritmo de optimización de descenso de gradiente utilizado en el entrenamiento de redes neuronales y en la optimización de funciones en el aprendizaje automático.
Fue propuesto por Yurii Nesterov en 1983 y es una mejora con respecto al descenso de gradiente estándar, especialmente en términos de velocidad de convergencia. El descenso de gradiente Nesterov se diferencia del descenso de gradiente tradicional en cómo se actualizan los parámetros del modelo.
En el descenso de gradiente Nesterov, en lugar de calcular el gradiente de la función de costo en la posición actual de los parámetros, se calcula el gradiente en una posición ligeramente adelantada de los parámetros. Luego, se utiliza ese gradiente para realizar la actualización de los parámetros. Esto tiene el efecto de "mirar hacia adelante" antes de dar el paso de actualización, lo que puede ayudar a reducir la oscilación y mejorar la velocidad de convergencia.
La fórmula para la actualización de los parámetros en el descenso de gradiente tipo Nesterov es la siguiente:
v = γ * v - η * ∇J(θ - γ * v)
θ = θ + v
Donde:
θ son los parámetros del modelo.
∇J(θ - γ * v) es el gradiente de la función de costo evaluado en la posición adelantada de los parámetros.
v es una especie de "momentum" que acumula la velocidad de los pasos anteriores.
η es la tasa de aprendizaje.
γ es un hiperparámetro que controla la influencia del momentum en la actualización.
En resumen, el descenso de gradiente tipo Nesterov es una técnica de optimización que tiene la ventaja de converger más rápidamente que el descenso de gradiente estándar, lo que lo hace especialmente útil en el entrenamiento de redes neuronales profundas y otros problemas de optimización en el aprendizaje automático.
CuadernoAula-B-28-OCT-18.py
-----------------------------------------------------------------------------
La clasificación de datos mediante árboles de decisiones es un método de aprendizaje automático que se utiliza para categorizar o etiquetar datos en diferentes clases o categorías. Es una técnica de modelado predictivo que se basa en la creación de un "árbol" de decisiones, donde cada nodo interno del árbol representa una pregunta o una prueba sobre una característica específica de los datos, y las ramas que salen de ese nodo conducen a diferentes resultados o decisiones basadas en el valor de esa característica. Los nodos hoja del árbol representan las categorías o clases en las que se divide el conjunto de datos.
El proceso de clasificación a través de árboles de decisión implica:
Construcción del árbol: Se inicia con un nodo raíz que representa todo el conjunto de datos. Luego, se selecciona una característica y un umbral que se utilizará para dividir los datos en dos subconjuntos. Este proceso se repite recursivamente en cada subconjunto hasta que se alcanza un criterio de parada, como un tamaño máximo de profundidad del árbol, una cantidad mínima de muestras en los nodos hoja, o una impureza mínima.
Selección de características: En cada paso de división, se elige la característica que mejor separa los datos, lo que se logra al minimizar alguna métrica de impureza, como el índice de Gini o la entropía. La característica y el umbral que minimizan la impureza se utilizan para dividir los datos en dos ramas.
Predicción: Una vez construido el árbol, se utiliza para hacer predicciones sobre datos nuevos. Los datos nuevos se introducen en el árbol, siguiendo las ramas que corresponden a las características de esos datos, hasta llegar a un nodo hoja que representa la clase predicha.
Los árboles de decisión son atractivos porque son interpretables y fáciles de visualizar. Sin embargo, pueden ser propensos al sobreajuste (overfitting), especialmente si se construyen árboles muy profundos. Para abordar este problema, se pueden utilizar técnicas como la poda (pruning) o el uso de bosques aleatorios (random forests) que combinan múltiples árboles para mejorar la precisión y reducir el sobreajuste.
En resumen, la clasificación de datos mediante árboles de decisión es una técnica poderosa y ampliamente utilizada en aprendizaje automático para tareas de clasificación, donde el objetivo es predecir la categoría o clase a la que pertenecen los datos de entrada en función de sus características.Ejercicio sencillo para aprendizaje de un descenso de gradiente tipo estocástico.
----------------------------------------------------------------------------------------------------------
Descenso de Gradiente Estocástico (Stochastic Gradient Descent, SGD):
El descenso de gradiente estocástico es un enfoque de optimización en el que se actualizan los parámetros del modelo utilizando un solo ejemplo de entrenamiento o un pequeño subconjunto de ejemplos (mini-batch) en cada iteración.
En cada iteración, se selecciona aleatoriamente un ejemplo o un mini-batch para calcular el gradiente y actualizar los parámetros.
SGD es mucho más eficiente computacionalmente que el muestreo histórico de costos y es especialmente útil cuando se tienen grandes conjuntos de datos, ya que permite un entrenamiento más rápido y escalable.
En resumen, el muestreo histórico de costos utiliza todo el conjunto de datos en cada iteración, mientras que el descenso de gradiente estocástico utiliza un subconjunto aleatorio de datos en cada iteración. SGD tiende a ser más ruidoso debido a su aleatoriedad, pero puede converger a una solución aceptable en menos iteraciones. Ambos enfoques tienen sus ventajas y desventajas, y la elección entre ellos depende de las características del problema y los recursos computacionales disponibles. También existen variantes intermedias, como el Mini-batch Gradient Descent, que utilizan un tamaño de mini-batch moderado para combinar eficiencia y estabilidad en el entrenamiento de modelos.
"""
Hilario Iglesias Martínez.
*****************************************
Ejercicio:
CuadernoEstocas-Aula-48-15-SEP-RV-2.py
-----------------------------------------
Ejecución:python3 CuadernoEstocas-Aula-48-15-SEP-RV-2.py
******************************************
Se prueba con los valores con pareamétros mínimos,
con el fin de apreciar su funcionamiento:
learning_rate = 0.01
n_iterations = 4
np.random.seed(0)
X = 2 * np.random.rand(4, 1)
y = 4 + 3 * X + np.random.randn(4, 1)
-------------------------------------------
Creado bajo plataforma Linux.
Ubuntu 20.04.6 LTS
Editado con Sublime Text.
Ejecutado bajo consola linux:
python3 CuadernoEstocas-Aula-48-15-SEP-RV-2.py
"""Hilario Iglesias Marínez
*******************************************************************
Ejercicio:
Estocástico_Aula_F-890.py
Ejecucion bajo Consola Linux:
python3 Estocástico_Aula_F-890.py
******************************************************************
Diferencias.
El descenso de gradiente es un algoritmo de optimización utilizado comúnmente en el aprendizaje automático y la optimización de funciones. Hay dos variantes principales del descenso de gradiente: el descenso de gradiente tipo Batch (también conocido como descenso de gradiente por lotes) y el descenso de gradiente estocástico. Estas dos variantes difieren en la forma en que utilizan los datos de entrenamiento para actualizar los parámetros del modelo en cada iteración.
Descenso de Gradiente Tipo Batch:
En el descenso de gradiente tipo Batch, se utiliza el conjunto completo de datos de entrenamiento en cada iteración del algoritmo para calcular el gradiente de la función de costo con respecto a los parámetros del modelo.
El gradiente se calcula tomando el promedio de los gradientes de todas las muestras de entrenamiento.
Luego, se actualizan los parámetros del modelo utilizando este gradiente promedio.
El proceso se repite hasta que se alcanza una convergencia satisfactoria o se ejecuta un número predefinido de iteraciones.
Descenso de Gradiente Estocástico (SGD):
En el descenso de gradiente estocástico, en cada iteración se selecciona una sola muestra de entrenamiento al azar y se utiliza para calcular el gradiente de la función de costo.
Los parámetros del modelo se actualizan inmediatamente después de calcular el gradiente para esa única muestra.
Debido a la selección aleatoria de muestras, el proceso de actualización de parámetros es inherentemente más ruidoso y menos suave que en el descenso de gradiente tipo Batch.
SGD es más rápido en cada iteración individual y a menudo converge más rápidamente, pero puede ser más ruidoso y menos estable en términos de convergencia que el descenso de gradiente tipo Batch.
Diferencias clave:
Batch GD utiliza todo el conjunto de datos en cada iteración, lo que puede ser costoso computacionalmente, mientras que SGD utiliza una sola muestra a la vez, lo que suele ser más eficiente en términos de tiempo.
Batch GD tiene una convergencia más suave y estable debido a que utiliza gradientes promedio, mientras que SGD es más ruidoso pero a menudo converge más rápido.
Batch GD puede quedar atrapado en óptimos locales, mientras que SGD puede escapar de ellos debido a su naturaleza estocástica.
En la práctica, también existen variantes intermedias como el Mini-Batch Gradient Descent, que utiliza un pequeño conjunto de datos (mini-lote) en lugar del conjunto completo, equilibrando así los beneficios de ambas técnicas. La elección entre estas variantes depende de la naturaleza del problema y las restricciones computacionales.
[
b]AulaF_658-Gradiente_Estocastico.py
*************************************************[/b]
El descenso de gradiente estocástico (SGD por sus siglas en inglés, Stochastic Gradient Descent) es un algoritmo de optimización ampliamente utilizado en el campo del aprendizaje automático y la inteligencia artificial para entrenar modelos de machine learning, especialmente en el contexto de aprendizaje profundo (deep learning). SGD es una variante del algoritmo de descenso de gradiente clásico.
La principal diferencia entre el descenso de gradiente estocástico y el descenso de gradiente tradicional radica en cómo se actualizan los parámetros del modelo durante el proceso de entrenamiento. En el descenso de gradiente tradicional, se calcula el gradiente de la función de pérdida utilizando todo el conjunto de datos de entrenamiento en cada paso de la optimización, lo que puede ser computacionalmente costoso en conjuntos de datos grandes.
En contraste, en SGD, en cada paso de optimización se utiliza un único ejemplo de entrenamiento (o un pequeño lote de ejemplos de entrenamiento) de forma aleatoria. Esto introduce estocasticidad en el proceso, ya que el gradiente calculado en cada paso se basa en una muestra aleatoria de datos. Como resultado, el proceso de optimización es más rápido y puede converger a un mínimo local o global de la función de pérdida de manera más eficiente en muchos casos.
Los pasos generales del algoritmo de descenso de gradiente estocástico son los siguientes:
Inicializar los parámetros del modelo de manera aleatoria o utilizando algún valor inicial.
Mezclar aleatoriamente el conjunto de datos de entrenamiento.
Realizar iteraciones sobre el conjunto de datos de entrenamiento, tomando un ejemplo (o un pequeño lote) a la vez.
Calcular el gradiente de la función de pérdida con respecto a los parámetros utilizando el ejemplo seleccionado.
Actualizar los parámetros del modelo utilizando el gradiente calculado y una tasa de aprendizaje predefinida.
Repetir los pasos 3-5 durante un número fijo de iteraciones o hasta que se cumpla un criterio de convergencia.
El uso de SGD es beneficioso en situaciones donde el conjunto de datos es grande o cuando se necesita un entrenamiento rápido. Sin embargo, la estocasticidad puede hacer que el proceso sea más ruidoso y requiera una sintonización cuidadosa de hiperparámetros, como la tasa de aprendizaje. Además, existen variantes de SGD, como el Mini-Batch Gradient Descent, que toman un pequeño lote de ejemplos en lugar de uno solo, lo que ayuda a suavizar las actualizaciones de parámetros sin la necesidad de calcular el gradiente en todo el conjunto de datos.Hilario Iglesias Martínez.
******************************************************************************************
ClaseAula-F896.py
***************************************************************************************
Este ejercicio, sencillo, para aprendizaje y seguimiento de los parámetros: peso,sesgo,costo, en un descenso de gradiente tipo Batch.
***************************************************************************************
Los términos "peso", "sesgo" y "costo" pueden tener diferentes significados dependiendo del contexto en el que se utilicen. Aquí te proporcionaré una breve descripción de cada uno de estos términos en diversos contextos:
Peso (Weight):
En el contexto de la física, el peso se refiere a la fuerza gravitatoria que actúa sobre un objeto debido a la atracción de la gravedad de la Tierra. Se mide en unidades de fuerza, como newtons o libras.
En el aprendizaje automático y la inteligencia artificial, un "peso" se refiere a los coeficientes asociados con las conexiones entre neuronas en una red neuronal. Estos pesos determinan la fuerza y dirección de la influencia de una neurona en otra dentro de la red. Los pesos se ajustan durante el proceso de entrenamiento de la red para que la red pueda aprender y realizar tareas específicas.
Sesgo (Bias):
En el contexto de la estadística y el análisis de datos, el sesgo se refiere a la tendencia sistemática de un conjunto de datos o un modelo estadístico a producir resultados que se desvían de la verdad o de la población real debido a errores sistemáticos en el proceso de recopilación o modelado de datos.
En el aprendizaje automático, el sesgo (bias) es un término que se utiliza para referirse a un valor constante añadido a la salida de una función en una red neuronal. El sesgo permite que la red pueda modelar funciones más complejas, desplazando la función de activación. Es una especie de "ajuste" que ayuda a la red a aprender y generalizar mejor.
Costo (Cost):
En el ámbito empresarial y financiero, el costo se refiere a la cantidad de recursos (dinero, tiempo, esfuerzo, etc.) que se requiere para producir o realizar algo. Puede incluir costos directos e indirectos.
En matemáticas y optimización, el costo es una medida de la cantidad que se desea minimizar o maximizar en un problema. Por ejemplo, en la optimización lineal, se busca minimizar una función de costo sujeta a ciertas restricciones.
En el contexto del aprendizaje automático y la optimización de modelos, el costo es una medida de cuán bien está funcionando un modelo en relación con los datos de entrenamiento y se utiliza para ajustar los parámetros del modelo durante el proceso de entrenamiento. El objetivo es minimizar el costo para que el modelo se ajuste mejor a los datos y pueda realizar predicciones precisas en nuevos datos.
Estos son conceptos que pueden ser ampliamente aplicados en diversos campos y contextos, por lo que su significado puede variar según el contexto específico en el que se utilicen.