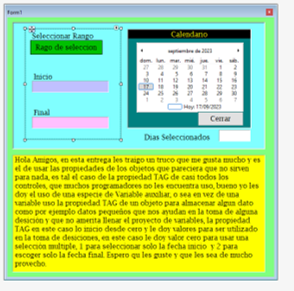
Mostrar los tags: n
Mostrando del 51 al 60 de 2.716 coincidencias
Se ha buscado por el tag: n
********************************
MiniBatch-Aula_228-B.py
******************************************************************************************
El descenso de gradiente mini batch, también conocido como Mini Batch Gradient Descent, es una variante del algoritmo de optimización del descenso de gradiente utilizado en el aprendizaje automático y la optimización de modelos de redes neuronales. A diferencia del descenso de gradiente estocástico (SGD) y el descenso de gradiente por lotes (Batch Gradient Descent), el descenso de gradiente mini batch combina características de ambos enfoques.
En el descenso de gradiente mini batch, los datos de entrenamiento se dividen en lotes más pequeños, cada uno de los cuales se utiliza para calcular una actualización parcial de los pesos del modelo. Estos lotes más pequeños se llaman "mini lotes". La idea detrás de esta técnica es encontrar un equilibrio entre la eficiencia de la actualización de parámetros y la variabilidad de las actualizaciones en comparación con el SGD y el Batch Gradient Descent.
Aquí hay una descripción paso a paso del proceso del descenso de gradiente mini batch:
División de los datos: Los datos de entrenamiento se dividen en mini lotes de tamaño fijo. El tamaño del mini lote es un hiperparámetro que se puede ajustar según las necesidades del problema. Por lo general, los tamaños de mini lotes varían desde 16 hasta 256 ejemplos, pero esto puede variar según el conjunto de datos y la arquitectura de la red.
Inicialización de pesos: Se inicializan los pesos del modelo de manera aleatoria o utilizando algún método de inicialización específico.
Cálculo del gradiente: Para cada mini lote, se calcula el gradiente de la función de pérdida con respecto a los pesos del modelo utilizando solo los ejemplos en ese mini lote. Esto se hace utilizando retropropagación (backpropagation).
Actualización de pesos: Los pesos del modelo se actualizan utilizando el gradiente calculado. La fórmula de actualización es similar a la del descenso de gradiente estocástico, pero en lugar de utilizar un solo ejemplo, se promedian los gradientes de todos los ejemplos en el mini lote. Esto suaviza las actualizaciones y reduce la variabilidad en comparación con el SGD.
Iteración: Se repiten los pasos 3 y 4 para cada mini lote. Este proceso se repite a lo largo de múltiples épocas hasta que se alcance un criterio de parada, como un número máximo de épocas o una convergencia satisfactoria.
Ventajas del descenso de gradiente mini batch:
Mayor eficiencia computacional en comparación con el Batch Gradient Descent, ya que se aprovecha el paralelismo en las operaciones matriciales.
Menor variabilidad en las actualizaciones de peso en comparación con el SGD, lo que puede llevar a una convergencia más rápida y estable.
El descenso de gradiente mini batch es una elección común para entrenar modelos de redes neuronales en la práctica, ya que combina las ventajas de SGD y Batch Gradient Descent. El tamaño del mini lote es un hiperparámetro crítico que debe ajustarse según el problema y la memoria disponible.[
]Estocastico-MSE-AULA-U856.py
************************************
El descenso de gradiente estocástico (SGD, por sus siglas en inglés, Stochastic Gradient Descent) es un algoritmo de optimización utilizado para entrenar modelos de aprendizaje automático, como regresiones lineales o redes neuronales, minimizando una función de costo, como el error cuadrático medio (MSE). El SGD es una variante del descenso de gradiente que utiliza un solo ejemplo de entrenamiento (o un pequeño grupo de ejemplos, conocido como mini-lote o minibatch) en cada paso de actualización en lugar de utilizar todo el conjunto de datos en cada paso.El siguiente programa genera valores hash para una contraseña, utilizando distintos algoritmos. También permite la copia de las salidas generadas.
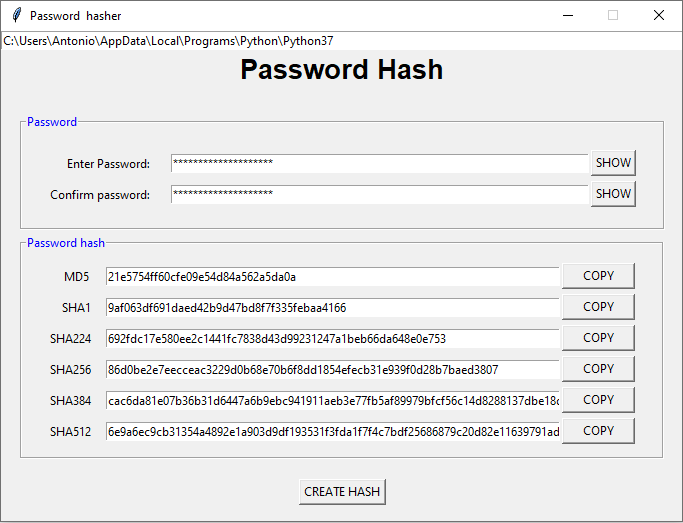
*******************************************************************
Ejercicio:
Estocástico_Aula_F-890.py
Ejecucion bajo Consola Linux:
python3 Estocástico_Aula_F-890.py
******************************************************************
Diferencias.
El descenso de gradiente es un algoritmo de optimización utilizado comúnmente en el aprendizaje automático y la optimización de funciones. Hay dos variantes principales del descenso de gradiente: el descenso de gradiente tipo Batch (también conocido como descenso de gradiente por lotes) y el descenso de gradiente estocástico. Estas dos variantes difieren en la forma en que utilizan los datos de entrenamiento para actualizar los parámetros del modelo en cada iteración.
Descenso de Gradiente Tipo Batch:
En el descenso de gradiente tipo Batch, se utiliza el conjunto completo de datos de entrenamiento en cada iteración del algoritmo para calcular el gradiente de la función de costo con respecto a los parámetros del modelo.
El gradiente se calcula tomando el promedio de los gradientes de todas las muestras de entrenamiento.
Luego, se actualizan los parámetros del modelo utilizando este gradiente promedio.
El proceso se repite hasta que se alcanza una convergencia satisfactoria o se ejecuta un número predefinido de iteraciones.
Descenso de Gradiente Estocástico (SGD):
En el descenso de gradiente estocástico, en cada iteración se selecciona una sola muestra de entrenamiento al azar y se utiliza para calcular el gradiente de la función de costo.
Los parámetros del modelo se actualizan inmediatamente después de calcular el gradiente para esa única muestra.
Debido a la selección aleatoria de muestras, el proceso de actualización de parámetros es inherentemente más ruidoso y menos suave que en el descenso de gradiente tipo Batch.
SGD es más rápido en cada iteración individual y a menudo converge más rápidamente, pero puede ser más ruidoso y menos estable en términos de convergencia que el descenso de gradiente tipo Batch.
Diferencias clave:
Batch GD utiliza todo el conjunto de datos en cada iteración, lo que puede ser costoso computacionalmente, mientras que SGD utiliza una sola muestra a la vez, lo que suele ser más eficiente en términos de tiempo.
Batch GD tiene una convergencia más suave y estable debido a que utiliza gradientes promedio, mientras que SGD es más ruidoso pero a menudo converge más rápido.
Batch GD puede quedar atrapado en óptimos locales, mientras que SGD puede escapar de ellos debido a su naturaleza estocástica.
En la práctica, también existen variantes intermedias como el Mini-Batch Gradient Descent, que utiliza un pequeño conjunto de datos (mini-lote) en lugar del conjunto completo, equilibrando así los beneficios de ambas técnicas. La elección entre estas variantes depende de la naturaleza del problema y las restricciones computacionales.
[
b]AulaF_658-Gradiente_Estocastico.py
*************************************************[/b]
El descenso de gradiente estocástico (SGD por sus siglas en inglés, Stochastic Gradient Descent) es un algoritmo de optimización ampliamente utilizado en el campo del aprendizaje automático y la inteligencia artificial para entrenar modelos de machine learning, especialmente en el contexto de aprendizaje profundo (deep learning). SGD es una variante del algoritmo de descenso de gradiente clásico.
La principal diferencia entre el descenso de gradiente estocástico y el descenso de gradiente tradicional radica en cómo se actualizan los parámetros del modelo durante el proceso de entrenamiento. En el descenso de gradiente tradicional, se calcula el gradiente de la función de pérdida utilizando todo el conjunto de datos de entrenamiento en cada paso de la optimización, lo que puede ser computacionalmente costoso en conjuntos de datos grandes.
En contraste, en SGD, en cada paso de optimización se utiliza un único ejemplo de entrenamiento (o un pequeño lote de ejemplos de entrenamiento) de forma aleatoria. Esto introduce estocasticidad en el proceso, ya que el gradiente calculado en cada paso se basa en una muestra aleatoria de datos. Como resultado, el proceso de optimización es más rápido y puede converger a un mínimo local o global de la función de pérdida de manera más eficiente en muchos casos.
Los pasos generales del algoritmo de descenso de gradiente estocástico son los siguientes:
Inicializar los parámetros del modelo de manera aleatoria o utilizando algún valor inicial.
Mezclar aleatoriamente el conjunto de datos de entrenamiento.
Realizar iteraciones sobre el conjunto de datos de entrenamiento, tomando un ejemplo (o un pequeño lote) a la vez.
Calcular el gradiente de la función de pérdida con respecto a los parámetros utilizando el ejemplo seleccionado.
Actualizar los parámetros del modelo utilizando el gradiente calculado y una tasa de aprendizaje predefinida.
Repetir los pasos 3-5 durante un número fijo de iteraciones o hasta que se cumpla un criterio de convergencia.
El uso de SGD es beneficioso en situaciones donde el conjunto de datos es grande o cuando se necesita un entrenamiento rápido. Sin embargo, la estocasticidad puede hacer que el proceso sea más ruidoso y requiera una sintonización cuidadosa de hiperparámetros, como la tasa de aprendizaje. Además, existen variantes de SGD, como el Mini-Batch Gradient Descent, que toman un pequeño lote de ejemplos en lugar de uno solo, lo que ayuda a suavizar las actualizaciones de parámetros sin la necesidad de calcular el gradiente en todo el conjunto de datos.Juego de tetris en pantalla grafica (modo 13), se maneja con las teclas de dirección y escape, para cambiar nivel + y -.
Juego de tetris en pantalla de texto, se maneja con las teclas de dirección y escape.
Para subir o bajar de nivel + y -.

-----------------------------------
Hilario Iglesias Martínez
*************************************
Este es un programa en Python
se realiza una regresión lineal
utilizando el método de gradiente descendente
(Batch Gradient Descent)
El programa realiza una regresión lineal utilizando
el método de gradiente descendente
y visualiza los resultados a través de
gráficas. Es una implementación simple
pero efectiva de un modelo de regresión lineal.
***********************************************
Programa realizado bajo una plataforma Linux:
Ubuntu 20.04.6 LTS.
Editado con: Sublime Text.
*********************************
Ejecución bajo consola Linux.
python3 ParaClaseLunes-Sep-F543.PY
*******************************************
"""*****************************************************************************************************
Hilario Iglesias Martínez
ClaseViernes-F543.py
DESCENSO DE GRADIENTE BATCH
*********************************************************************************************************
El "descenso de gradiente tipo Batch" es una técnica de optimización utilizada en el aprendizaje automático y la estadística para ajustar los parámetros de un modelo matemático, como una regresión lineal o una red neuronal, de manera que se minimice una función de costo específica. Es una de las variantes más simples y fundamentales del descenso de gradiente.
Aquí tienes una explicación de cómo funciona el descenso de gradiente tipo Batch:
Inicialización de parámetros: Comienza con un conjunto inicial de parámetros para tu modelo, que generalmente se eligen de manera aleatoria o se establecen en valores iniciales.
Selección de lote (Batch): En el descenso de gradiente tipo Batch, se divide el conjunto de datos de entrenamiento en lotes o subconjuntos más pequeños. Cada lote contiene un número fijo de ejemplos de entrenamiento. Por ejemplo, si tienes 1000 ejemplos de entrenamiento, puedes dividirlos en lotes de 32 ejemplos cada uno.
Cálculo del gradiente: Para cada lote, calculas el gradiente de la función de costo con respecto a los parámetros del modelo. El gradiente es una medida de cómo cambia la función de costo cuando se hacen pequeños ajustes en los parámetros. Indica la dirección en la que debes moverte para minimizar la función de costo.
Actualización de parámetros: Después de calcular el gradiente para cada lote, promedias los gradientes de todos los lotes y utilizas ese gradiente promedio para actualizar los parámetros del modelo. Esto se hace multiplicando el gradiente promedio por una tasa de aprendizaje (learning rate) y restando ese valor de los parámetros actuales. El learning rate controla el tamaño de los pasos que das en la dirección del gradiente.
Repetición: Los pasos 2-4 se repiten varias veces (llamadas épocas) a través de todo el conjunto de datos de entrenamiento. Cada época consiste en procesar todos los lotes y ajustar los parámetros del modelo.
Convergencia: El proceso de ajuste de parámetros continúa hasta que se alcanza un criterio de convergencia, que generalmente se establece en función de la precisión deseada o el número de épocas.
El descenso de gradiente tipo Batch es eficiente en términos de cómputo, ya que utiliza todos los datos de entrenamiento en cada paso de actualización de parámetros. Sin embargo, puede ser lento en conjuntos de datos grandes, y su convergencia puede ser más lenta en comparación con otras variantes del descenso de gradiente, como el descenso de gradiente estocástico (SGD) o el mini-batch SGD.
En resumen, el descenso de gradiente tipo Batch es una técnica de optimización que ajusta los parámetros de un modelo mediante el cálculo y la actualización de gradientes en lotes de datos de entrenamiento, con el objetivo de minimizar una función de costo. Es una parte fundamental en la optimización de modelos de aprendizaje automático.
*********************************************************************************************************
Ejecucion.
Bajo consola de Linux.
python3 ClaseViernes-F543.py