Desarrollo de aplicaciones conducidas por datos
Desarrollo de aplicaciones conducidas por datos
199 visualizaciones el último mes
SQL Server
,Bases de Datos
Publicado el 10 de Junio del 2019 por Gnomi
3.943 visualizaciones desde el 10 de Junio del 2019
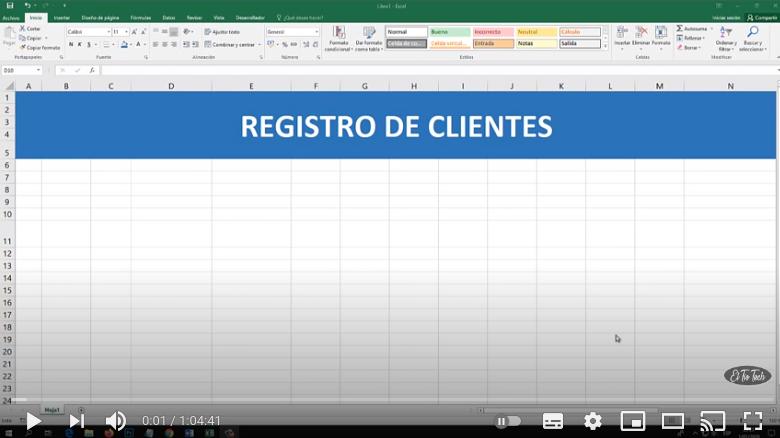
Desarrollo de aplicaciones conducida por bases de datos

Nos adentramos en el desarrollo de aplicaciones y cuando escribimos código, independientemente del lenguaje de programación que se utilice, la primera opción, la mas “plana”, aunque la que genera mas texto, es la del “código rígido”.
Nos adentramos en el desarrollo de aplicaciones y cuando escribimos código, independientemente del lenguaje de programación que se utilice, la primera opción, la mas “plana”, aunque la que genera mas texto, es la del “código rígido”.