Espectrometría
Python
Publicado el 30 de Agosto del 2024 por Hilario (145 códigos)
434 visualizaciones desde el 30 de Agosto del 2024
Propongo el sencillo ejercicio en phyton : Aula_28_Ag.24_Espectro_Masas.py. Este ejercicio elabora una pequeña simulación planteando una espectrometría de una molécula de agua. Explicaremos, previamente un poco, en que consiste las espectrometría de masas.
-----------------------------------------------------------------------------------------------------------------------------------
La espectrometría de masas (MS, por sus siglas en inglés) es una técnica analítica utilizada para medir la relación masa/carga (m/z) de los iones presentes en una muestra. En el contexto de una molécula, como la del agua (H₂O), la espectrometría de masas permite identificar y cuantificar los fragmentos iónicos que resultan de la ionización de la molécula, lo que a su vez proporciona información sobre su estructura molecular y su composición.
Principios Básicos de la Espectrometría de Masas
Ionización:
-------------
La muestra, que puede ser un sólido, líquido o gas, se introduce en el espectrómetro de masas, donde se somete a un proceso de ionización. Este proceso convierte las moléculas en iones cargados (generalmente positivos) al agregar o quitar electrones.
Existen varios métodos de ionización, como la ionización por impacto electrónico (EI), electrospray (ESI), y ionización química (CI), entre otros.
Aceleración:
---------------
Los iones generados se aceleran mediante un campo eléctrico, de modo que todos los iones con la misma carga tengan la misma energía cinética.
Deflexión:
------------
Los iones acelerados pasan a través de un campo magnético o eléctrico que los desvía en función de su relación masa/carga (m/z). Los iones más ligeros y con una mayor carga se desvían más que los iones más pesados.
Detección:
-------------
Los iones desviados impactan en un detector que mide la intensidad de la señal, la cual está relacionada con la cantidad de iones presentes. La intensidad se registra para cada valor de m/z, generando así un espectro de masas.
Interpretación del Espectro de Masas
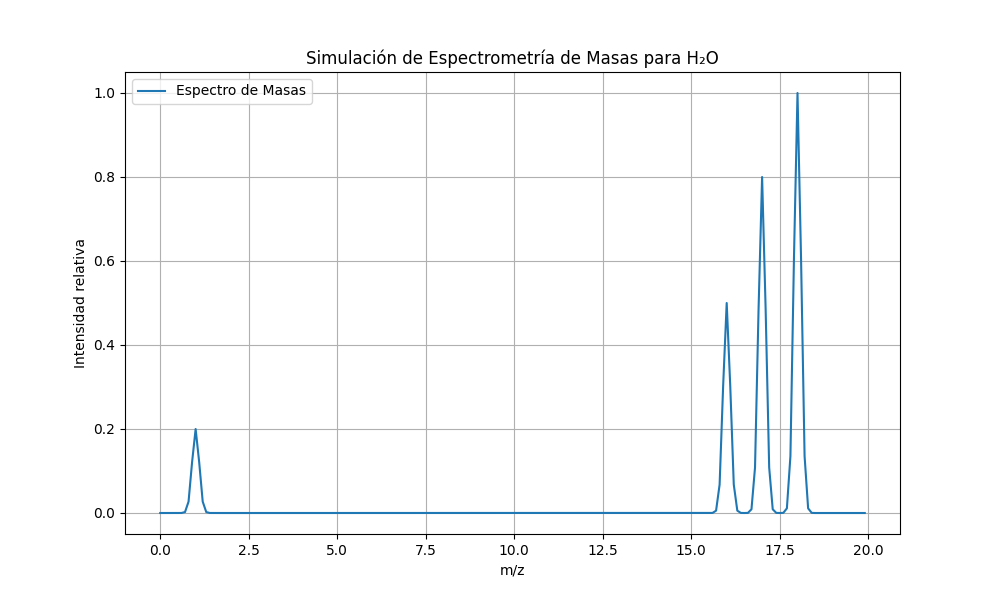
El resultado de la espectrometría de masas es un gráfico denominado espectro de masas, donde:
Eje X: Representa la relación masa/carga (m/z) de los iones.
Eje Y: Representa la intensidad o abundancia relativa de los iones detectados.
Cada pico en el espectro corresponde a un ion con una relación m/z específica. La altura del pico indica la cantidad relativa de ese ion en la muestra.
Aplicación a la Molécula de Agua (H₂O)
-----------------------------------------------------------
Para una molécula simple como el agua, la espectrometría de masas puede revelar varios iones, dependiendo del método de ionización:
----------------------------------------------------------------------------------------------------------------------------------
H₂O⁺ (m/z = 18): Ion molecular de agua sin fragmentar.
OH⁺ (m/z = 17): Fragmento ionizado que resulta de la pérdida de un átomo de hidrógeno.
O⁺ (m/z = 16): Ion de oxígeno, que podría resultar de la fragmentación de la molécula.
H⁺ (m/z = 1): Ion de hidrógeno.
En un espectro de masas de agua, podrías ver picos en estos valores de m/z, reflejando la presencia de estos fragmentos iónicos.
Ejemplo de Uso en Química y Biología.
---------------------------------------------------
Identificación de Compuestos: Al comparar el espectro de masas de una muestra con espectros de referencia, los químicos pueden identificar compuestos desconocidos.
Determinación de Estructuras Moleculares: La forma en que una molécula se fragmenta puede proporcionar pistas sobre su estructura química.
Cuantificación de Análisis: La espectrometría de masas también se usa para cuantificar la cantidad de un compuesto en una muestra, especialmente en el análisis de mezclas complejas.
Conclusión
La espectrometría de masas es una herramienta poderosa para estudiar las propiedades de las moléculas al identificar sus fragmentos iónicos y medir sus relaciones masa/carga. En la práctica, esta técnica tiene aplicaciones en química, biología, farmacología y muchas otras disciplinas científicas.
******************************************************************************************
Simulación del Espectro de Masas
--------------------------------------------------------
El espectro de masas para una molécula de agua podría incluir los siguientes iones:
H₂O → m/z = 18 (ion molecular)
OH → m/z = 17
O → m/z = 16
H → m/z = 1
Explicación del Código:
Fragmentos y sus m/z: Definimos las relaciones m/z para diferentes fragmentos posibles de la molécula de agua (H2O+, OH+, O+, H+).
Intensidades Relativas: Asignamos intensidades relativas a estos picos basadas en la probabilidad de fragmentación.
Espectro Simulado: Generamos un espectro de masas añadiendo picos gaussianos centrados en los valores de m/z definidos.
Visualización: El gráfico muestra la relación masa/carga (m/z) en las abscisas y la intensidad relativa en las ordenadas.
Resultado:
Al ejecutar este código, obtendrás un gráfico que simula un espectro de masas para una molécula de agua, donde se visualizan los diferentes iones generados por la fragmentación de la molécula. Este es un modelo simplificado, pero proporciona una base para entender cómo se podrían visualizar los datos obtenidos en un espectrómetro de masas.
-------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------
El ejercicio fue realizado en una plataforma linux. Concretamente en: Ubuntu 20.04.6 LTS.
Fue editado con Sublime text.
Ejecutado bajo consola Linux con el siguiente comando:
python3 Aula_28_Ag.24_Espectro_Masas.py
Se deberán tener cargados los siguientes módulos:
import numpy as np
import matplotlib.pyplot as plt
Ejecutado con python en versión:3
-------------------------------------------------------