Mostrar los tags: c
Mostrando del 81 al 90 de 2.875 coincidencias
Se ha buscado por el tag: c
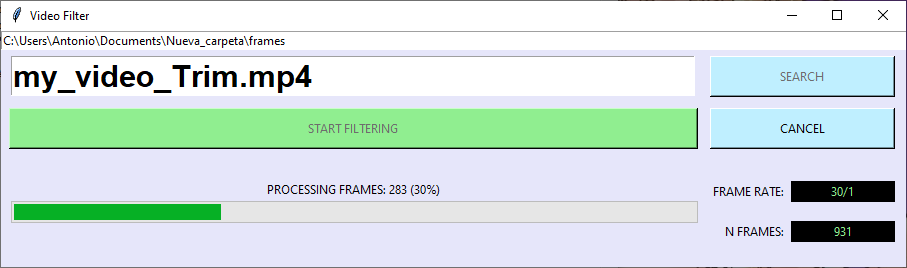
El presente programa se encarga de aplicar filtros sobre los fotogramas de un archivo de video empleando diferentes funciones. El programa realiza el filtrado frame a frame para a continuación generar un nuevo video con la secuencia de frames procesados (aplicando el frame rate del vídeo original). También usa el software "ffmpeg" para copiar el audio del vídeo original y añadirlo al vídeo resultante.
USO: Primeramente seleccionaremos el vídeo a filtrar mediante el botón "SEARCH". Una vez seleccionado iniciaremos el proceso con "START FILTERING" con el que empezaremos seleccionando la ubicación del nuevo vídeo, para a continuación iniciar el proceso (NOTA: La ruta del directorio de destino no deberá contener espacios en blanco). El proceso de filtrado podrá ser cancelado medinate el botón "CANCEL".
PARA CUALQUIER DUDA U OBSERVACIÓN USEN LA SECCIÓN DE COMENTARIOS.
Nueva versión del juego de la serpiente con caracteres ASCII. Esta versión se diferencia de las dos anteriores (que pueden verse en mi lista de códigos) en que se acompaña de un archivo (de nombre "hiScore") que irá almacenando de modo permanente, la puntuación máxima alcanzada por el jugador.
BOTONES:
Mover serpiente: Botones de dirección
Pause y reanudar partida pausada : Barra espaciadora.
Finalizar partida en curso: tecla "q"
PARA CUALQUIER PROBLEMA, NO DUDEN EN COMUNICÁRMELO.
El ejercicio, es el siguiente:
Ejercicio_Clas_Regre_Log-Aula-28.py
La clasificación de datos por regresión logística es una técnica de aprendizaje automático que se utiliza para predecir la pertenencia de un conjunto de datos a una o más clases. Aunque el nombre "regresión" logística incluye la palabra "regresión", este enfoque se utiliza para problemas de clasificación en lugar de regresión.
La regresión logística se emplea cuando se desea predecir la probabilidad de que una observación pertenezca a una categoría o clase específica, generalmente dentro de un conjunto discreto de clases. Por lo tanto, es una técnica de clasificación que se utiliza en problemas de clasificación binaria (dos clases) y clasificación multiclase (más de dos clases). Por ejemplo, se puede usar para predecir si un correo electrónico es spam (clase positiva) o no spam (clase negativa) o para clasificar imágenes en categorías como gatos, perros o pájaros.
La regresión logística utiliza una función logística (también conocida como sigmoide) para modelar la probabilidad de pertenecer a una clase particular en función de variables de entrada (características). La función sigmoide tiene la propiedad de que produce valores entre 0 y 1, lo que es adecuado para representar probabilidades. El modelo de regresión logística utiliza coeficientes (pesos) para ponderar las características y calcular la probabilidad de pertenencia a una clase.
Durante el entrenamiento, el modelo busca ajustar los coeficientes de manera que las probabilidades predichas se ajusten lo más cerca posible a las etiquetas reales de los datos de entrenamiento. Una vez que se ha entrenado el modelo, se puede utilizar para predecir la probabilidad de pertenencia a una clase para nuevos datos y tomar decisiones basadas en esas probabilidades, como establecer un umbral para la clasificación en una clase específica.
*************************************************************************************************************
Los pasos que realizamos en el ejercicio, son los siguientes:
1-Generamos datos sintéticos donde la clase se determina por la suma de las dos características.
2-Implementamos la regresión logística desde cero sin el uso de scikit-learn, incluyendo el cálculo de 3-gradientes y la actualización de pesos.
4-Dibujamos los datos de entrada en un gráfico, junto con la línea de decisión que separa las clases.
En resumen, la regresión logística es una técnica de clasificación que modela las probabilidades de pertenencia a clases utilizando la función sigmoide y es ampliamente utilizada en una variedad de aplicaciones de aprendizaje automático.[center]
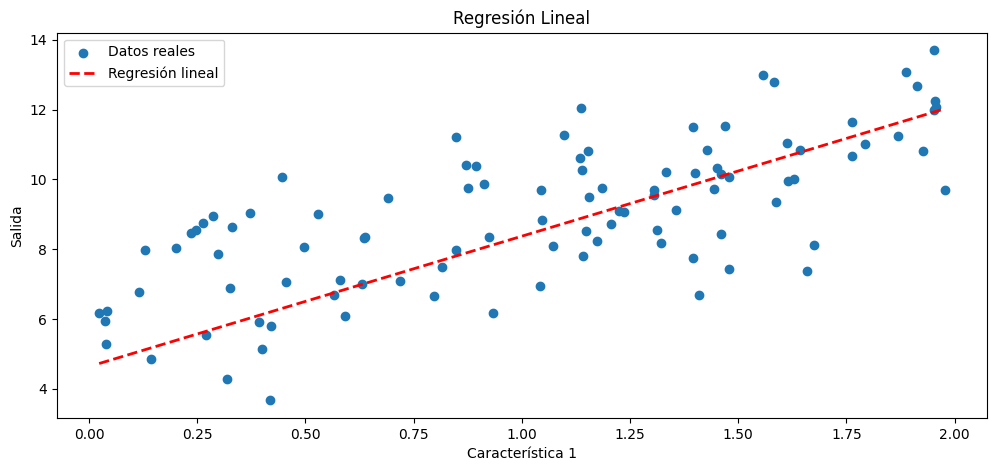 En este sencillo ejercicio:Descn_Mult_Momentun_Ejemp_Aula-28-Oct.py, tratamos de explicar como realizar un descenso de gradiente multiple, aplicando al mismo un momentum, para regular un descenso de gradiente , digamos, rápido de forma que el mismo no sea errático.
En este sencillo ejercicio:Descn_Mult_Momentun_Ejemp_Aula-28-Oct.py, tratamos de explicar como realizar un descenso de gradiente multiple, aplicando al mismo un momentum, para regular un descenso de gradiente , digamos, rápido de forma que el mismo no sea errático.
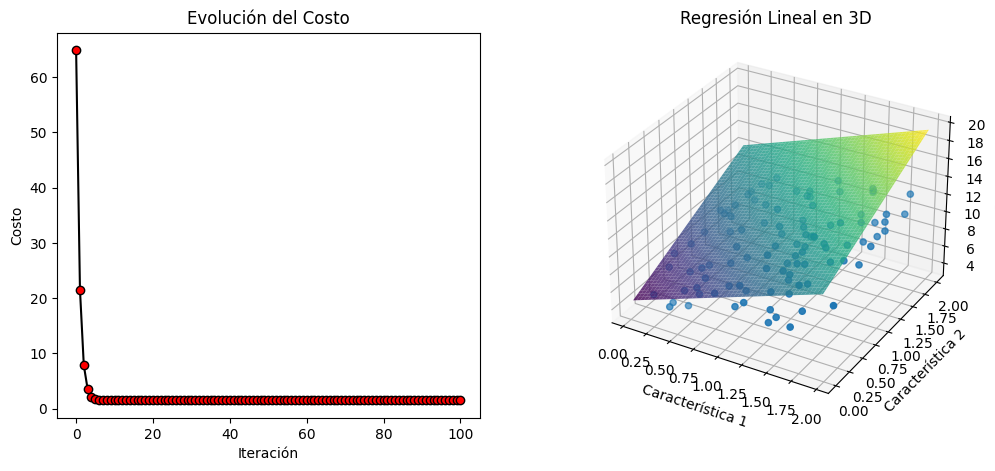
Una regresión múltiple es un tipo de análisis de regresión en el que se busca modelar la relación entre una variable de respuesta (dependiente) y múltiples variables predictoras (independientes o características). En otras palabras, en lugar de predecir una única variable de respuesta a partir de una única característica, se intenta predecir una variable de respuesta a partir de dos o más características. La regresión múltiple puede ser útil para comprender cómo varias características influyen en la variable de respuesta.
Cuando aplicas "momentum" a un algoritmo de regresión, normalmente estás utilizando una variante del descenso de gradiente llamada "descenso de gradiente con momentum." El momentum es una técnica que ayuda a acelerar la convergencia del algoritmo de descenso de gradiente, especialmente en problemas en los que el parámetro de costo es irregular, o tiene pendientes pronunciadas. En lugar de utilizar únicamente el gradiente instantáneo en cada iteración, el descenso de gradiente con momentum tiene en cuenta un promedio ponderado de los gradientes pasados, lo que le permite mantener una especie de "momentum" en la dirección de la convergencia.
A continuación, os proporcionaré un ejemplo de regresión múltiple con descenso de gradiente con momentum,y datos sintéticos en Python. En el mismo utilizamos, aparte de otras, la biblioteca NumPy para generar datos sintéticos, y aplicar el descenso de gradiente con momentum.
También se incluye en el ejercicio, una disposición de graficas, para hacerlo más didactico. El alunmno, podrá jugar, o experimentar con los parámetros iniciales e hiperparámetros, para seguir su evolución.
En resumen este es un ejercicio sencillo, que explicaremos en clase, paso a paso, para su comprensión. Como siempre utilizaremos en nuestros ordenadores la plataforma Linux, con Ubuntu 20. También realizaremos la práctica en Google Colab.
python3 Ejercicio_Aula_23_Momentum.py
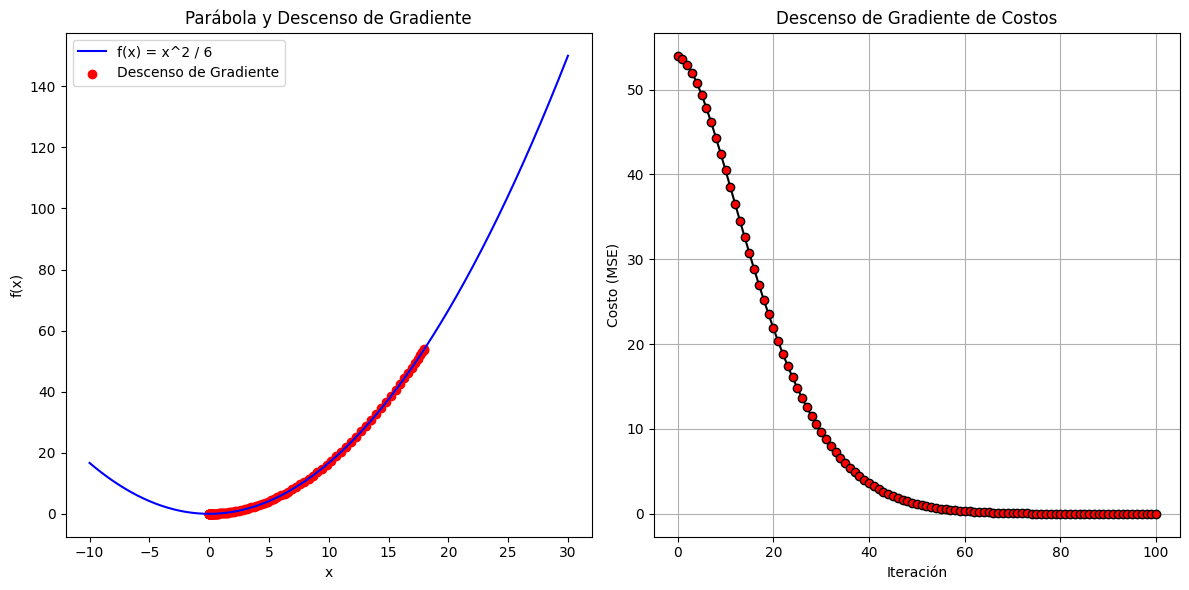
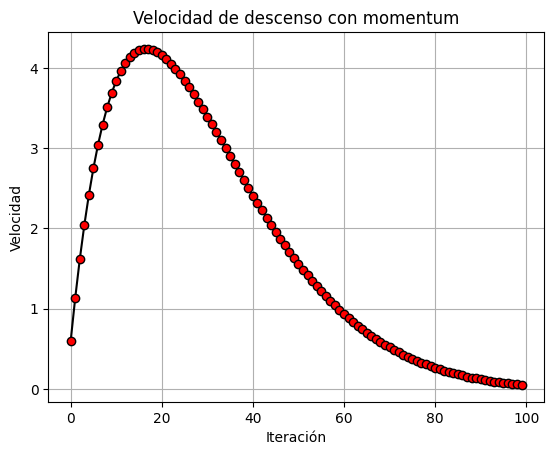
Sencillo ejercicio sobre un descenso de gradiente con momento, (Gradient Descent with Momentum en inglés).
Se trata de aplicar este algoritmo a una funcion parabolica del tipo: f(x) = x^2 / 6.
Cuya derivada es:x**2 / 6.
El descenso de gradiente con momento es una variante del algoritmo de descenso de gradiente utilizado en la optimización y entrenamiento de modelos de aprendizaje automático, particularmente en el contexto de redes neuronales y problemas de optimización no convexos. Su objetivo es acelerar la convergencia del descenso de gradiente y ayudar a evitar quedarse atrapado en óptimos locales.
La principal diferencia entre el descenso de gradiente con momento y el descenso de gradiente estándar es la adición de un término de "momentum" o impulso. En el descenso de gradiente estándar, en cada iteración, el gradiente actual se utiliza directamente para actualizar los parámetros del modelo. En cambio, en el descenso de gradiente con momento, se mantiene un promedio ponderado exponencial de los gradientes anteriores y se utiliza ese promedio para actualizar los parámetros.
El objetivo del término de momento es suavizar las actualizaciones de los parámetros y reducir las oscilaciones que pueden ocurrir cuando el gradiente varía significativamente en diferentes direcciones. Esto puede ayudar a acelerar la convergencia y a sortear barreras o mínimos locales en la función de costo
En este sencillo ejercicio que propongo, en vez de utilizar datos sintéticos de caráctear aleatorio de entrada, lo vamos a aplicar a una función parabólica.
*****************************************************************************************************************
Repaso-Des-Gra-Batch-Aula-E.28-OCT-24.py
******************************************************************************************************************
Realizar un descenso de gradiente tipo Batch, en código python, desde el punto x=8.03, y=5.846. De la funcion f(x)=x**2/x+3. Cuya derivada es: f'(x)=x+3. Se incluye grafica de costos MSE, y grafica de la parábola, con los valores del descenso, marcado en puntos sobre la misma.El descenso de gradiente tipo Adam, o simplemente Adam (por Adaptive Moment Estimation), es un algoritmo de optimización utilizado en el campo del aprendizaje automático y la inteligencia artificial para ajustar los parámetros de un modelo de manera que se minimice una función de pérdida. Adam es una variante del descenso de gradiente estocástico (SGD) que combina técnicas de otros algoritmos de optimización para mejorar la convergencia y la eficiencia en la búsqueda de los mejores parámetros del modelo.
Aquí hay una explicación simplificada de cómo funciona el algoritmo Adam:
Inicialización de parámetros: Se inician los parámetros del algoritmo, como la tasa de aprendizaje (learning rate), los momentos de primer y segundo orden, y se establece un contador de iteraciones.
Cálculo del gradiente: En cada iteración, se calcula el gradiente de la función de pérdida con respecto a los parámetros del modelo. Esto indica en qué dirección deben ajustarse los parámetros para reducir la pérdida.
Cálculo de momentos de primer y segundo orden: Adam mantiene dos momentos acumulativos, uno de primer orden (media móvil de los gradientes) y otro de segundo orden (media móvil de los gradientes al cuadrado).
Actualización de parámetros: Se utilizan los momentos calculados en el paso anterior para ajustar los parámetros del modelo. Esto incluye un término de corrección de sesgo para tener en cuenta el hecho de que los momentos se inicializan en cero. La tasa de aprendizaje también se aplica en esta etapa.
Iteración y repetición: Los pasos 2-4 se repiten durante un número especificado de iteraciones o hasta que se cumpla un criterio de parada, como la convergencia.
Adam se considera una elección popular para la optimización de modelos de aprendizaje profundo debido a su capacidad para adaptar la tasa de aprendizaje a medida que se entrena el modelo, lo que lo hace efectivo en una variedad de aplicaciones y evita problemas como la convergencia lenta o la divergencia en el entrenamiento de redes neuronales. Sin embargo, es importante ajustar adecuadamente los hiperparámetros de Adam, como la tasa de aprendizaje y los momentos, para obtener un rendimiento óptimo en un problema específico.CuadernoAula-B-28-OCT-18.py
-----------------------------------------------------------------------------
La clasificación de datos mediante árboles de decisiones es un método de aprendizaje automático que se utiliza para categorizar o etiquetar datos en diferentes clases o categorías. Es una técnica de modelado predictivo que se basa en la creación de un "árbol" de decisiones, donde cada nodo interno del árbol representa una pregunta o una prueba sobre una característica específica de los datos, y las ramas que salen de ese nodo conducen a diferentes resultados o decisiones basadas en el valor de esa característica. Los nodos hoja del árbol representan las categorías o clases en las que se divide el conjunto de datos.
El proceso de clasificación a través de árboles de decisión implica:
Construcción del árbol: Se inicia con un nodo raíz que representa todo el conjunto de datos. Luego, se selecciona una característica y un umbral que se utilizará para dividir los datos en dos subconjuntos. Este proceso se repite recursivamente en cada subconjunto hasta que se alcanza un criterio de parada, como un tamaño máximo de profundidad del árbol, una cantidad mínima de muestras en los nodos hoja, o una impureza mínima.
Selección de características: En cada paso de división, se elige la característica que mejor separa los datos, lo que se logra al minimizar alguna métrica de impureza, como el índice de Gini o la entropía. La característica y el umbral que minimizan la impureza se utilizan para dividir los datos en dos ramas.
Predicción: Una vez construido el árbol, se utiliza para hacer predicciones sobre datos nuevos. Los datos nuevos se introducen en el árbol, siguiendo las ramas que corresponden a las características de esos datos, hasta llegar a un nodo hoja que representa la clase predicha.
Los árboles de decisión son atractivos porque son interpretables y fáciles de visualizar. Sin embargo, pueden ser propensos al sobreajuste (overfitting), especialmente si se construyen árboles muy profundos. Para abordar este problema, se pueden utilizar técnicas como la poda (pruning) o el uso de bosques aleatorios (random forests) que combinan múltiples árboles para mejorar la precisión y reducir el sobreajuste.
En resumen, la clasificación de datos mediante árboles de decisión es una técnica poderosa y ampliamente utilizada en aprendizaje automático para tareas de clasificación, donde el objetivo es predecir la categoría o clase a la que pertenecen los datos de entrada en función de sus características.Solucion al problema por el metodo de paso atras.